
性能优化学习笔记13
Cilk 实时系统
回顾cilk程序
我们回顾之前学过的关于并行程序的内容,这里主要是关于cilk的程序,关于一个triple nested loop的矩阵乘法的例子。
1 | for(int i = 0; i < N; i++) { |
这里我们令串行执行的时间为,同时我们令Cilk下的矩阵乘法的时间为,(在P个处理器下执行)。理想情况下,满足:
我们仅仅需要在程序上加上cilk的关键字,就可以实现并行化的程序。这里我们需要注意的是,我们需要在程序上加上cilk的关键字,同时我们需要在编译器上加上cilk的编译器选项。
那么实际上,cilk是怎么做scheduling的呢?
Cilk的scheduling
从宏观的角度去看cilk,它主要是负责特定的运行时系统负责在并行处理器和多核系统上面,对计算任务进行调度和负载均衡。因此在我们使用完关键词之后,cilk的调度器将这种计算映射到多个处理器上面,同时负责调度和负载均衡。同时它能够在运行时进行动态的调整,根据可用处理资源灵活调整,并且采用随机化的工作窃取调度器,确保这种映射的高效性。
编译器都会生成什么?
之前我们学过的关于foo函数,里面是一个递归的程序,而这里为了简单做了修改,以便于理解,那么cilk的编译器会生成什么呢?
1 | int foo(int n){ |
经过Cilk compiler之后,会生成较多的内容,这里将会从上而下进行解释。包括下面的六个部分
Cilk运行时系统所需的一些基本功能
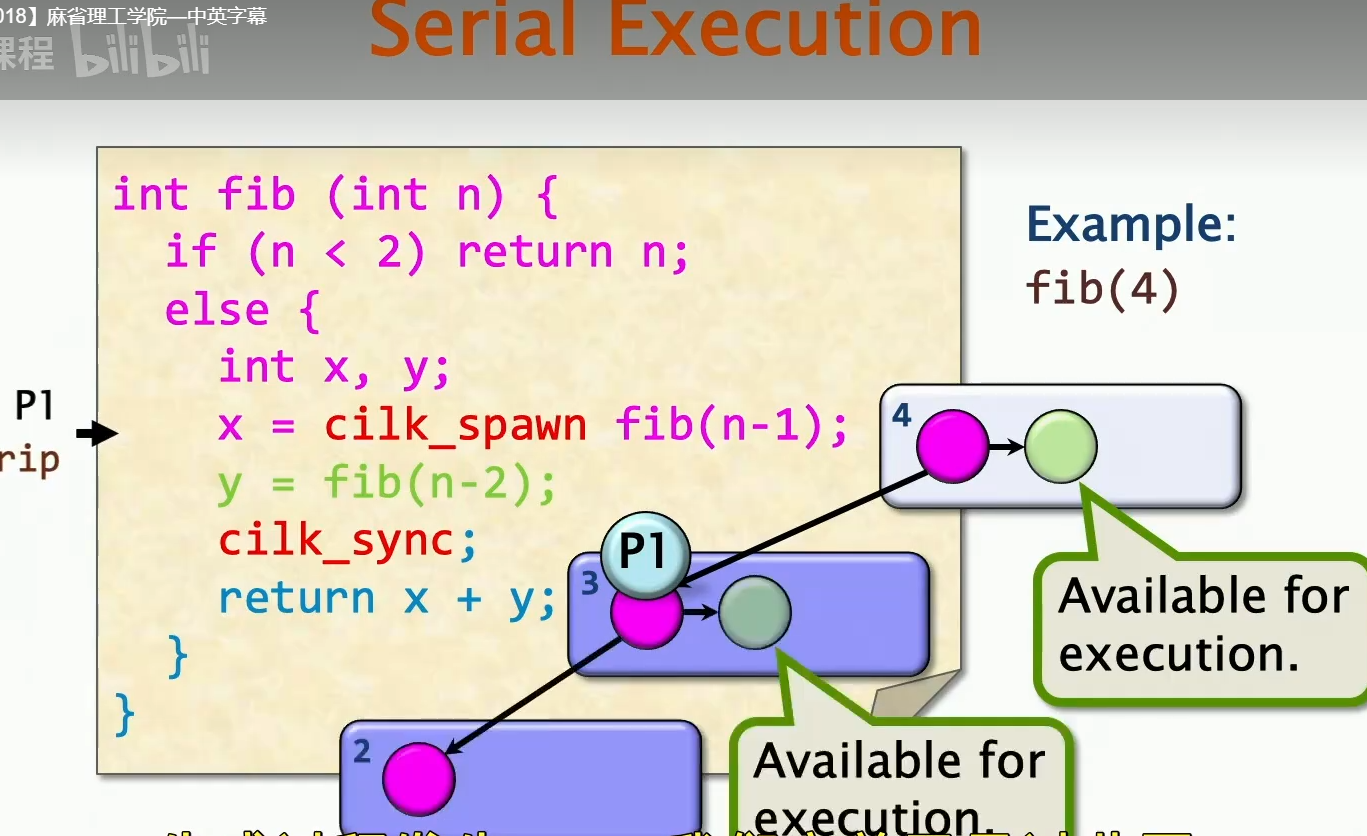
上图是关于一个串行执行的情况,这里的P1处理器在进入递归的时候,实际上本函数里面还有未执行完的部分,这部分是Available的,是可以供于其他处理器进行执行。
于是,下图便是对于steal情况的讲解:
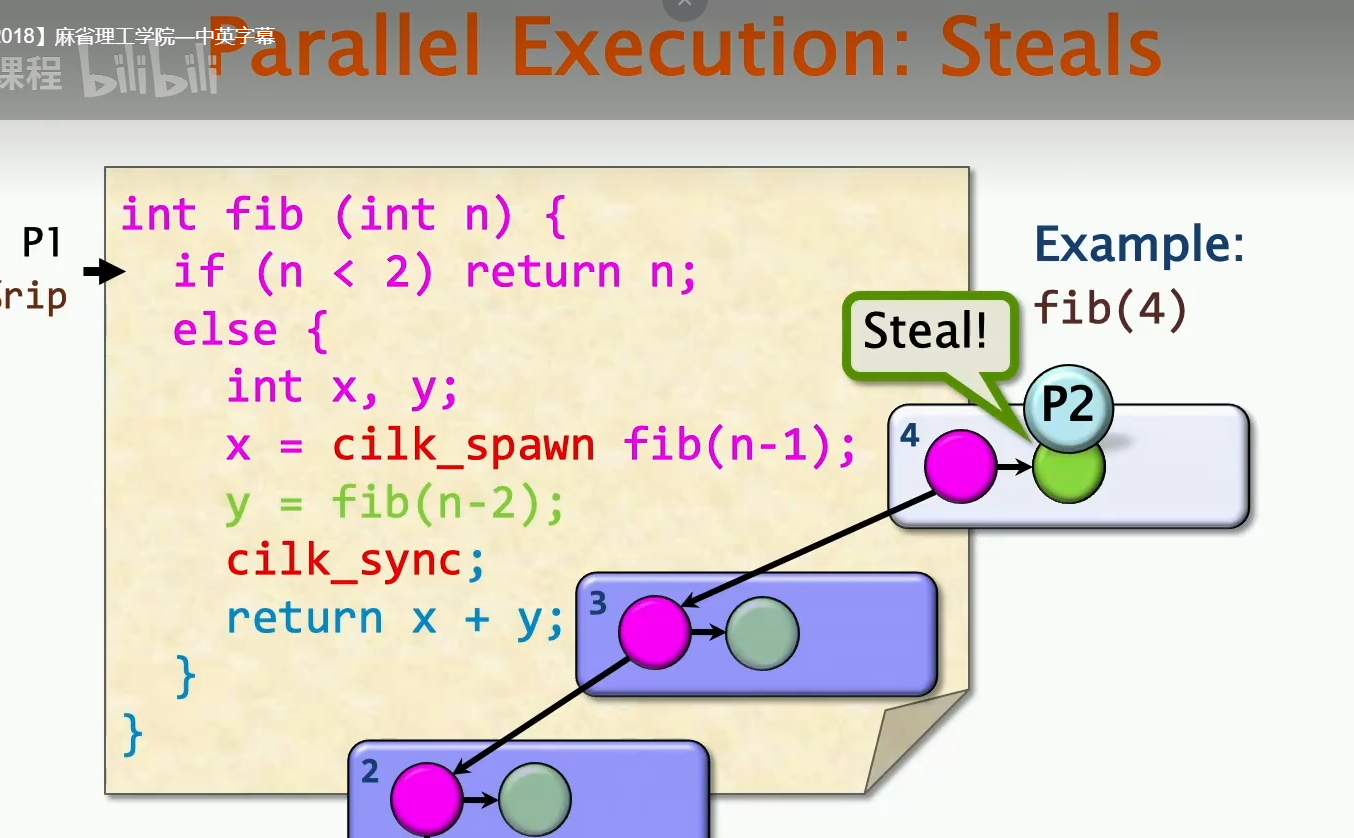
这里的P2处理器在执行的时候,发现P1处理器有一部分的任务是Available的,于是P2处理器便会去steal这部分的任务。
以下有一些问题需要考究:
**第一个问题如下:**一个单一的worker必须能够像串行计算一样去计算自己的计算任务。
第二个问题如下:
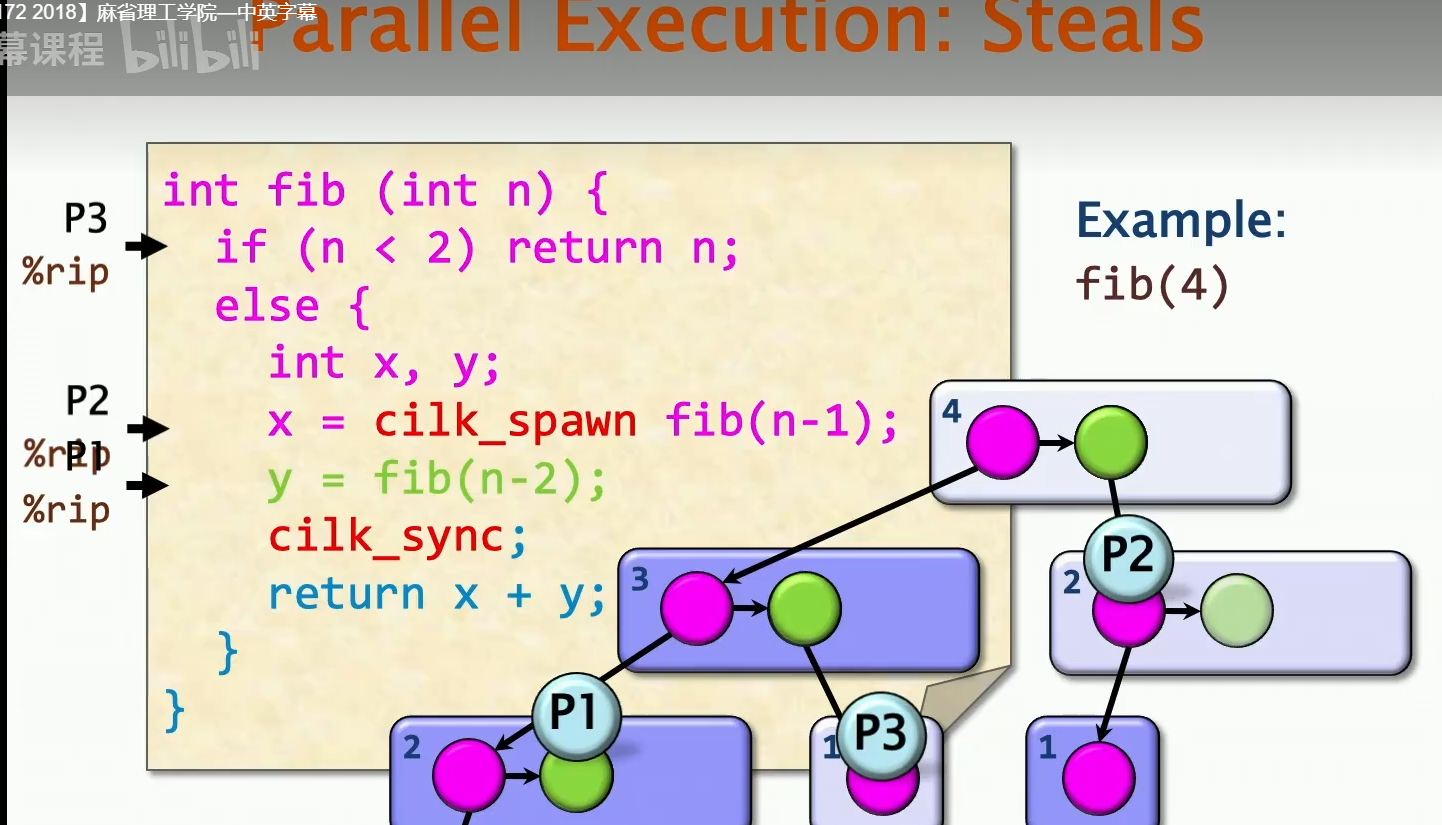
上图中P1已经return,P3steal了绿色部分然后深入,以及P2进入了n=4的绿色并深入,其实这个时候有一个非常重要的问题:也就是P2、P3这种处理器是怎么做到在函数运行的中间跳转进行执行的?很明显n=4的时候,绿色的部分是剩下的部分,P2是怎么找到这个部分的呢?
**第三个问题在于:**当我们遇到同步的问题,我们该如何处理?

这里,P3处理器准备返回,返回后,P1还没有执行完,我们都知道,这个程序后面接着cilk_sync语句,但是很明显这里的P3并不能完成同步这个任务,因为P1还没有执行完(也就是fib(2)还没有执行完),那么这个时候我们该如何处理呢?那么很明显,这种嵌套的计算下,我们怎么进行cilk_sync的等待呢?这是第二个问题。
**第四个问题在于:**之前我们学过cactus stack,这里的cilk系统,遵循C语言的指针规则,就是子任务可以访问父任务帧的指针,但是父任务并不能访问子任务帧。同时,在cilk系统中,每一个处理器,就是每一个worker,都有自己的独立的栈视图,但是这些视图并不一定是独立的。如下:
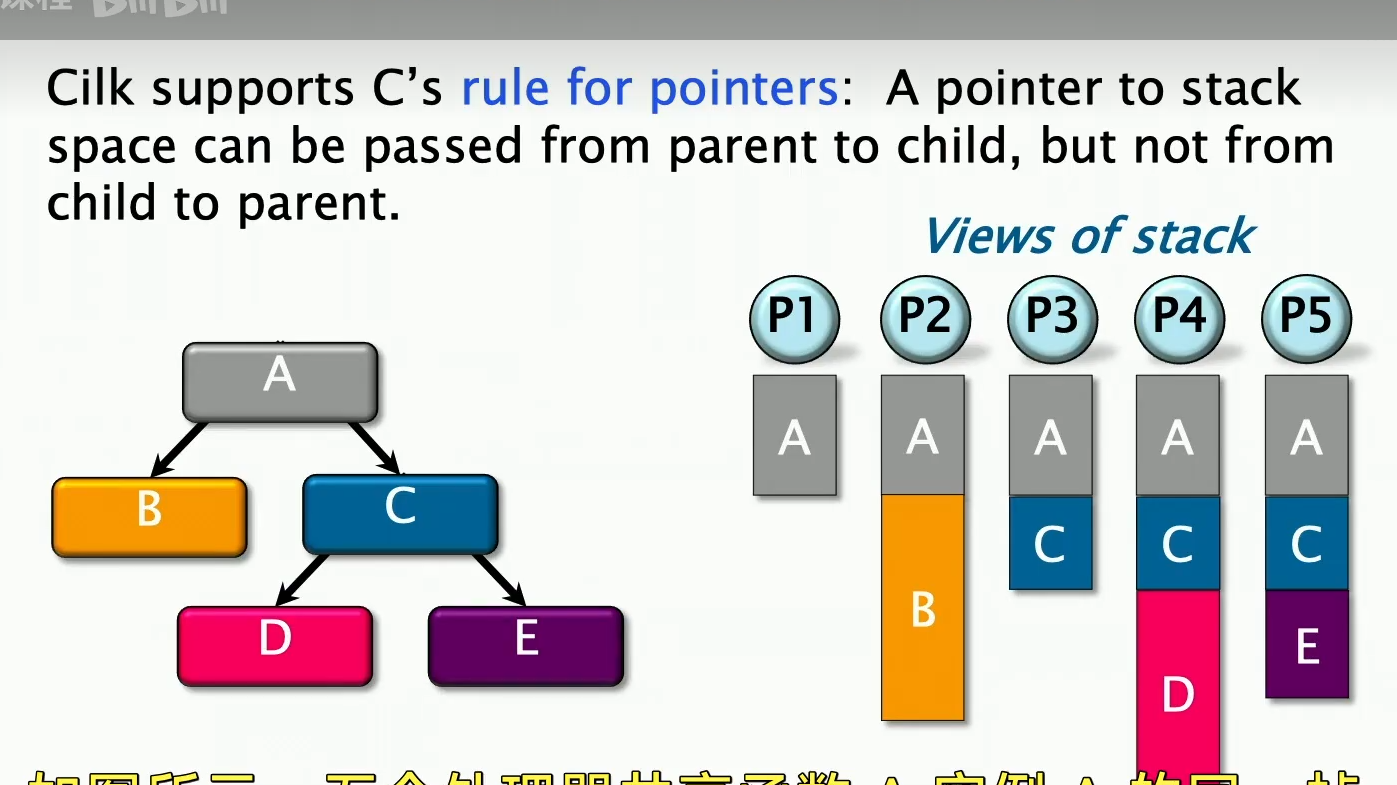
这里P1-P5都有A的视图,而P3-P5拥有C的视图,因此,cilk要保证这些视图既可以访问,又是一致的(并非完全相同,类似我们缓存一致性)。cilk必须以某种方式实现这种Cactus stack。
**第五个问题:**如果发生steal的情况,这里的thieves必须能够去handle派生的帧和调用的帧。
性能考量
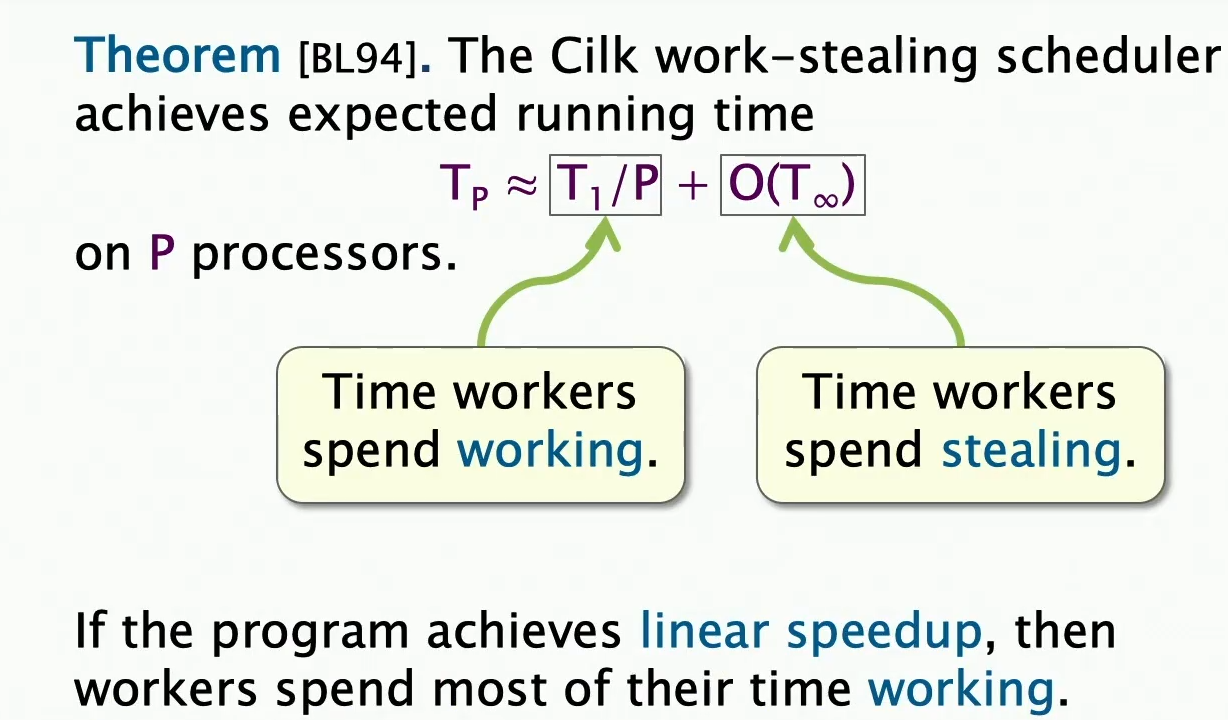
系统中workers在实际工作上花费的时间,也就是实际任务的时间:,而后面的一部分是workers互相窃取的时间,我们并不希望这部分时间过多,因为这部分时间是浪费的。同时,我们希望在给定的处理器数目下,我们的程序能够得到线性的加速,那就意味着我们希望cilk系统中工作者的大部分时间都是在进行有效的工作。
其实,除了我们关注于并行下的计算时间,我们也关注这样的并行时间与serial的情况进行比较,我们想知道并行的性能和串行的性能相比,是否有提升。
我们希望:
在有效的并行度下面,有:
也就是P个处理器下的运行时间与等于一个处理器下的运行时间除以P。
同时,我们的目标是:
这也就意味着:>,也就是说,我们希望在并行下的工作量和串行下的工作量相差不大。也就是之前说的两点:
- 足够的并行性:
- high work efficiency:
Cilk对于这种并行工作的主要原则就是:work-first principal
基本的worker deque
1 | int foo(int n){ |
为了便于分析,给出了这样一个程序,这里的foo我们称为spawning function,而barz是spawned by foo,baz的调用则是spawn的延续。
worker deque的设计如下所示:
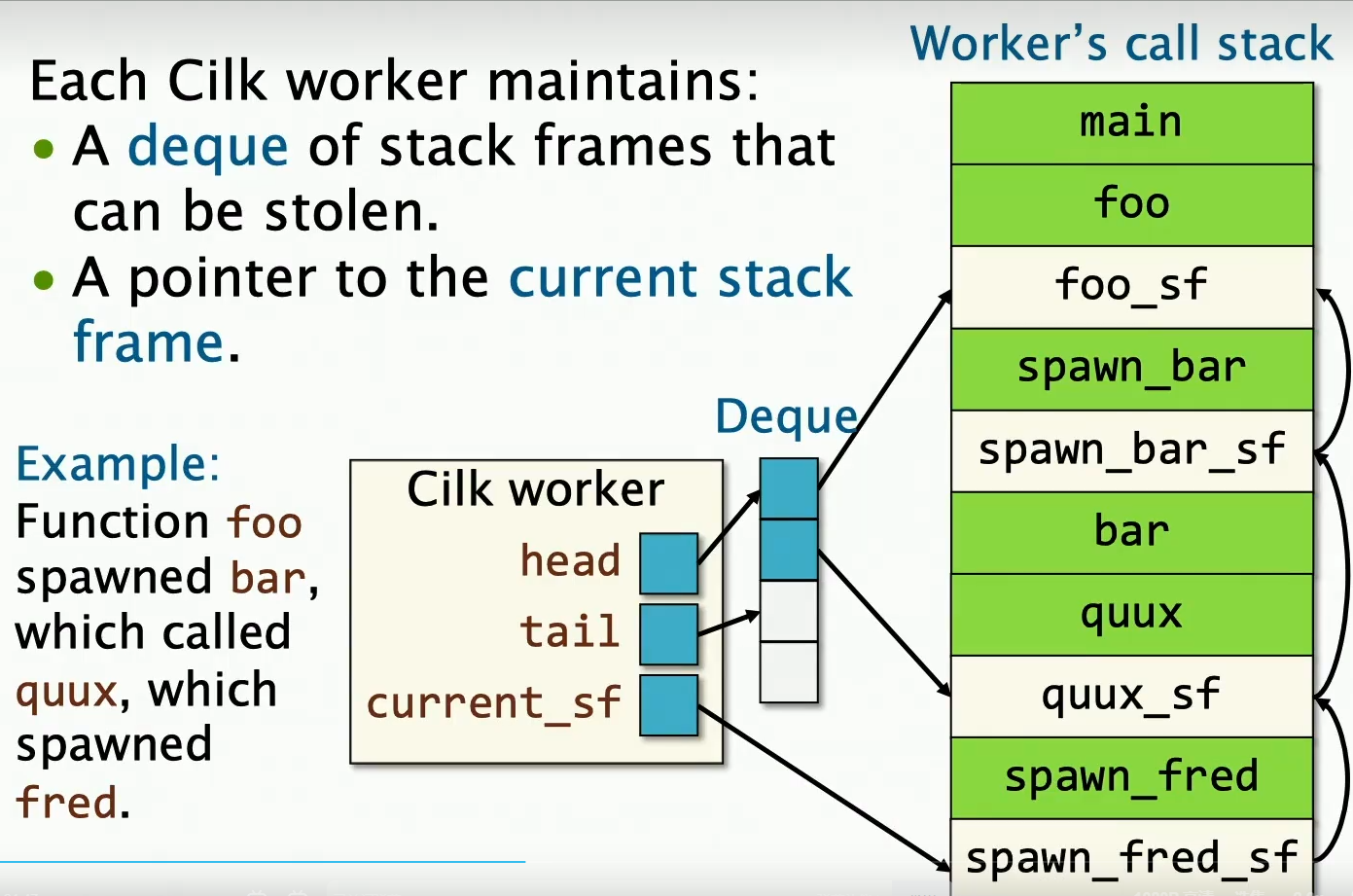
这里有一个deque存放可以被窃取的stack frames,而current_sf指向的是当前正在执行的stack frame,这个不能被窃取,因此不在deque中。
其中对于cilk程序进行编译后,会有两个编译后的函数:
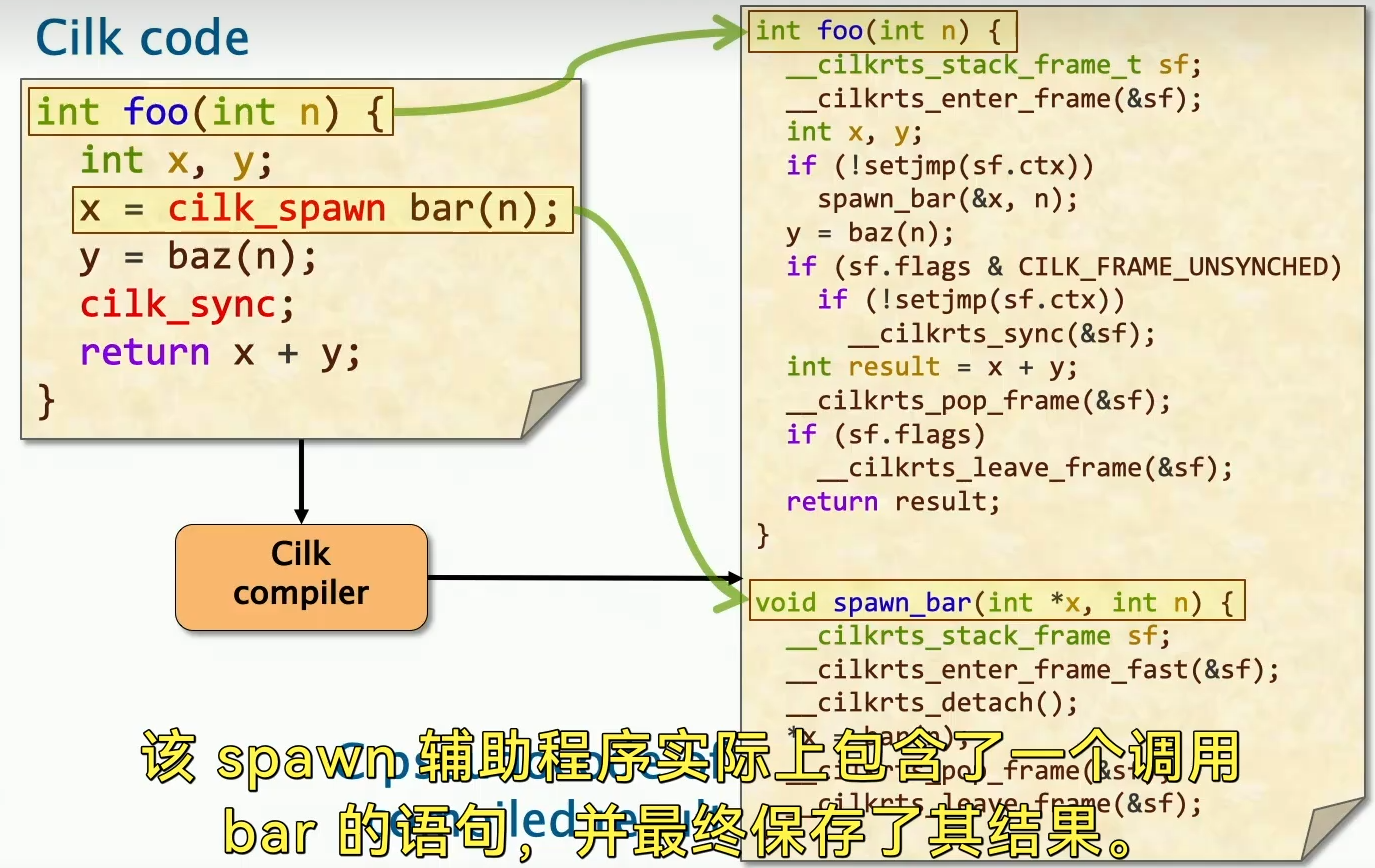
一个是foo,也就是spawn函数,另一个是spawn helper,这个辅助程序包含了一个调用bar的语句,并最终保存 bar的返回值。
Spawning computation(任务派生具体是怎么工作的?)
以下是关于spawn function以及spawn helper的C的伪代码:
1 | int foo(int n){ |
1 | void spawn_bar(int *x, int n){ |
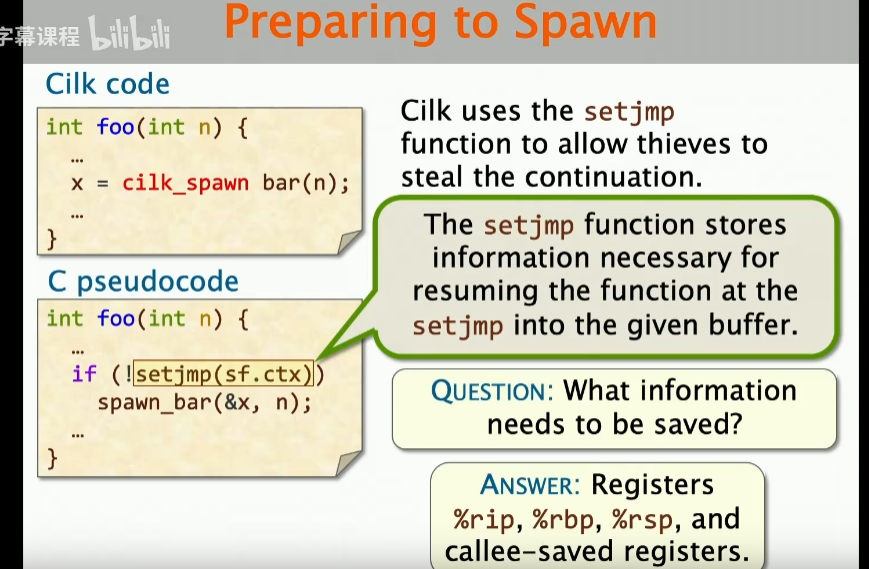
为了确保持续运行,这里的setjmp函数用于存储恢复函数所需的必要信息,其中就包括一些堆栈指针、寄存器信息,那么是哪些寄存器需要去维护呢?这里就是callee的registers,也就是callee-saved registers,这些寄存器是需要去维护的。
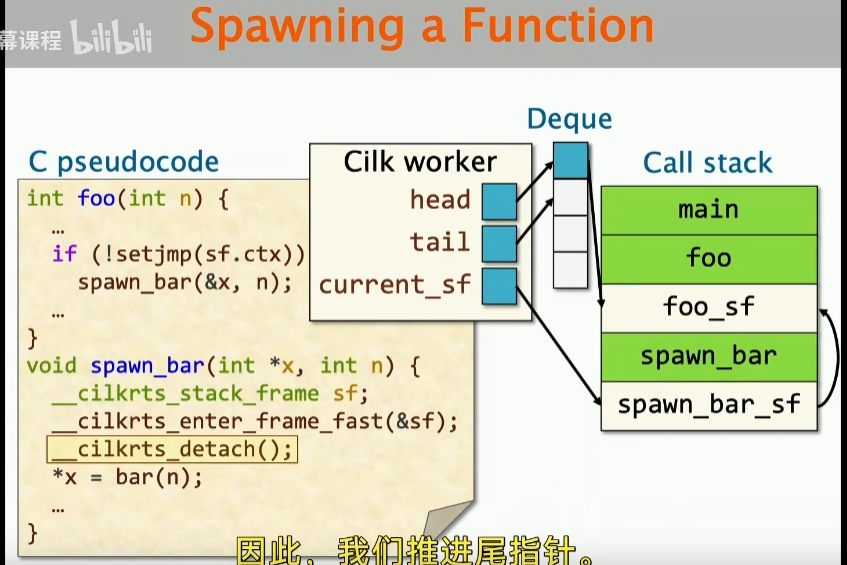
当我们进入了这个spawning helper之后,很自然我们要去更新当前栈调用栈的状态,这里就是current_sf指向改变,同时子stack frame要指向父stack frame,同时这是deque就可以加入新的元素了,因为这个是可以被steal的。(图中的spawn_bar_sf目前没有被加入进去是因为deque 的定义,只是可以被steal的加进去)
Stealing computation
实际上对于steal,就是去窃取victim的the top of the deque,我们这里做具体的说明:
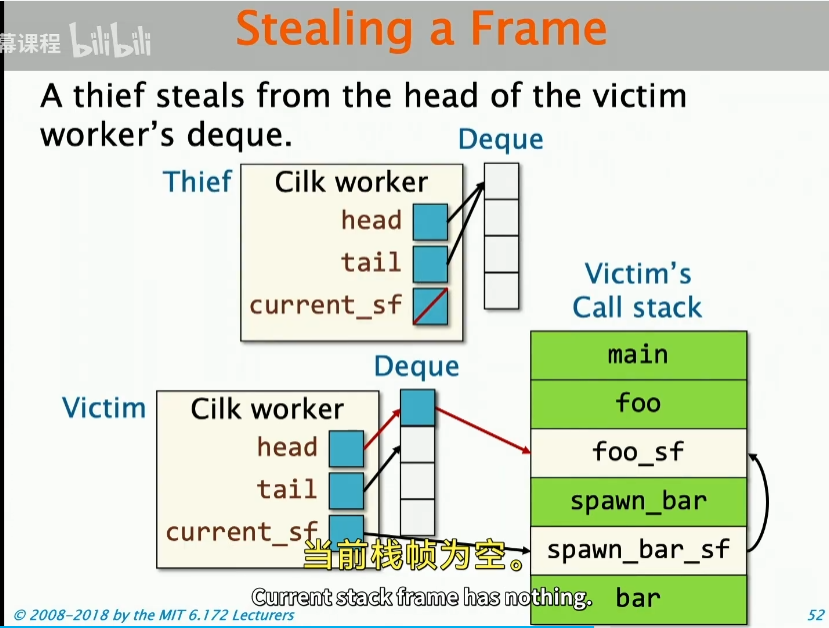
这是一开始的关于thief和victim的结构图,这里的thief会做什么操作呢?
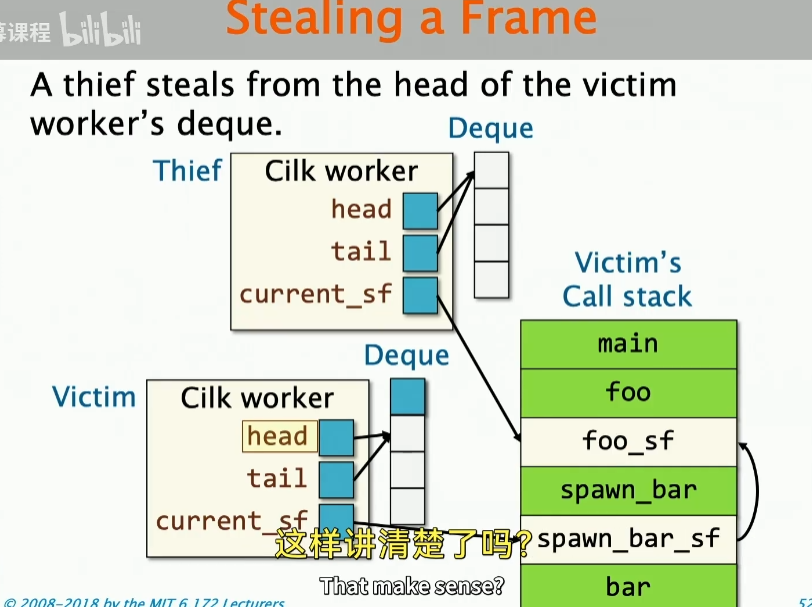
这里的主要操作是对准victim的head pointer, head pointer指向的是deque的头部,这里的操作是去窃取victim的deque的头部,pointer向前移动,并且把thief的current_sf指向victim call stack的stack frame
实际上,要实现这种功能有点复杂,因为victim和thief是位于不同的处理器上面的,此场景涉及大量的指针转移,我们考虑这种过程的时候,需要处理victim的deque的并发访问,这里解决并发访问主要涉及 THE protocol:

从一个全局的角度去考虑,这里的thief在对deque进行steal的时候,总是先获取一个lock,而对于worker来说,优化程度高一点,并不是都会去获取lock,对于工作者,会首先尝试去pop一个frame,而仅仅当弹出操作失败的时候,才会去获取lock。也就是仅仅当失败的时候,才会在这个deque上面增加lock来看看是否可以成功。其实这个也就是我们之前看到的关于leave frame routine
好了,现在我们已经理解完thief怎么去进行steal的操作,又有一个比较重要的问题在于,当这个thief要恢复一个延续状态(名词称为stolen continuation)的时候,我们该如何处理呢?(也就是这个thief要jumping into the millde of the function,尽管这些状态都是由另外一个处理器做出来的,但是这个thief必须想象出正确的state,并开始继续执行)
这就和那个 setjmp和long jmp函数有关了:
首先,对于这两个函数的理解如下:
在 C 语言中,setjmp 和 longjmp 函数提供了一种实现非局部跳转的机制,通常用于异常处理。它们允许程序从某个函数中跳出,并返回到一个之前保存的程序状态,而不必通过正常的函数调用返回机制。
setjmp: 这个函数用于保存当前的执行环境(包括栈帧、寄存器等信息)。调用setjmp时,程序会记录下当前的程序状态,并返回一个整数值。longjmp: 这个函数可以恢复由setjmp保存的执行环境,并“跳回”到保存的状态。它会让程序重新进入setjmp,但这次返回的是一个非零值,而不是最初调用时返回的0
然后,我们看到在foo函数,也就是spawn function中,我们看见了这个setjmp函数,这个函数是将一些当前的状态保存到了本地缓存里面,也就是保存到了call 栈中的foo栈帧的缓冲区,目前这个thief已经构建了这个cilk工作结构,其中thief的 current_sf指向的就是这个foo的栈帧。
当thief要去恢复这个stolen continuation的时候,我们需要去调用longjmp函数,它会跳回到同一个栈帧中的setjmp函数,但是这个时候,这里的setjmp()函数的返回结果就是1(非false),那么这样就自然而然跳过了spawn_bar函数,接着去运行baz函数去了,设计十分巧妙!
实际上,这里的longjmp(current_sf->ctx,1)具体是这样子的,用的是同一个buffer,这里我们把longjmp叫做the complement of setjmp

Cactus stack
实际上,对于函数来说,除了寄存器状态,还有一些其他的状态,比如函数的局部变量,函数的参数,函数的返回地址等等,这些都是需要去保存的,这些状态存在于stack中,而对于每一个thief来说,它都有自己的stack视图,也就是说我们要去实现这种cactus stack。
实际上,Cilk是通过pointer trick来实现这种cactus stack的:
在说这个之前,我们先考虑一个问题:如果我们让thief直接去访问victim的stack,这样是不是会有问题呢?实际上是有问题的,比如在victim的 call stack中,我们的thief 接着要去执行baz函数,但是实际上这里还有其他函数调用的状态,就是 spawn bar这些函数,thief的行为会破坏victim的栈。
但是有一点要知道,我们确实是想要share一些数据,比如我们都想知道foo这个函数的状态,因此需要一个独立的调用栈。
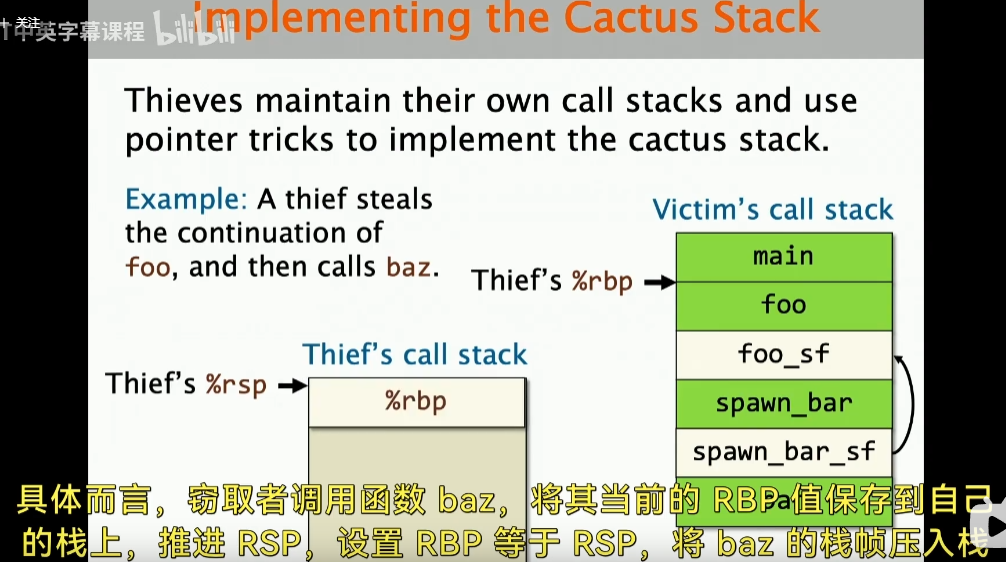
如上图所示,这里的thief调用栈,它自己的rbp指针指向的是foo,也就是victim call stack 的foo地址,然后,如果thief想要调用函数,那么就保存rbp的值(把当前rbp的值压入自己的栈里面)
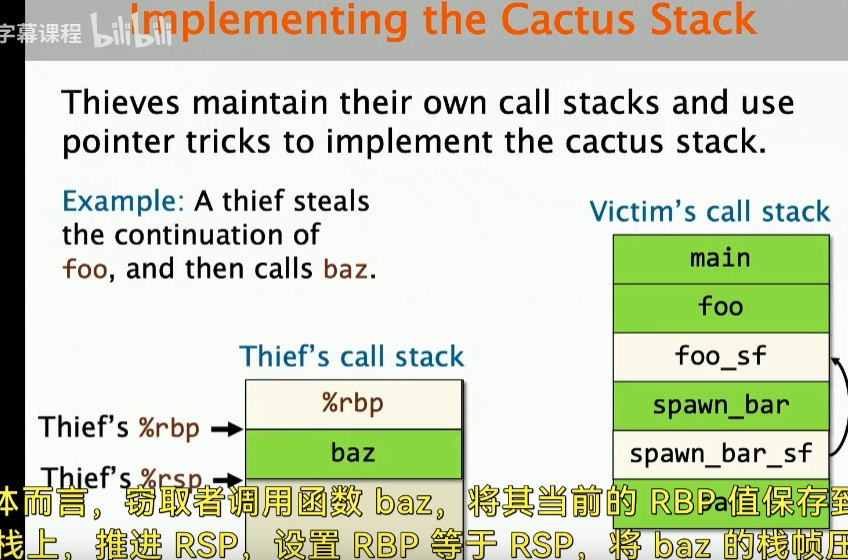
然后我们向前推进rbp,更新rsp,这样就可以实现cactus stack了。
Synchronizing computation
关于同步的问题,这里主要讲解了full frame synchronization,有一个关于full frame tree的讲解,因为是动画演示,这里不做赘述了。
 wechat
wechat alipay
alipay