
性能优化学习笔记12
并行存储分配
上一节课的相关回顾
- Allocation
void* malloc(size_t s); 其作用为分配并返回一个指针指向一个大小至少为s个字节的内存块 - Aligned Allocation
void* memalign(size_t alignment, size_t s); 其作用为分配并返回一个指针指向一个大小至少为s个字节的内存块,并且这个内存块的地址是alignment的倍数,并且alignment必须是2的幂次方。 - Deallocation
void free(void *p); 其作用为释放指针p指向的内存块
为什么我们要去做内存对齐?
- 为了做cache line对齐,提高cache的命中率
- 矢量化指令要求数据对齐
Virtual Memory Allocation
mmap()
mmap() 是一种系统调用,通常它将磁盘上面的文件映射到内存中,但是它也可以用来分配虚拟内存,无需映射文件。
1 | void *p = mmap(0, // don't care where |
上述mmap的作用就是在应用程序的地址空间中找到一个连续的未使用区域,该区域足够大以容纳size字节,然后它会更新页表,然后操作系统内部创建必要的虚拟内存管理。(操作系统会通过一个叫做页表的数据结构,将虚拟内存地址映射到物理内存地址。这个过程叫做地址转换。当你的程序访问某个虚拟地址时,硬件会自动的通过页表,找到对应的物理地址,然后访问这个物理地址。妈的前几年我都是白学了?怎么到现在才清楚了!)
Properties of mmap()
mmap() 比较懒,当你请求一个虚拟内存的时候,它并不会立即分配物理内存,而是等到你访问这个虚拟内存的时候,才会分配物理内存。
mmap() 与 malloc()的区别
实际上malloc和free都是属于内存分配,其都是堆管理代码的接口。而堆管理代码使用现有的系统函数,比如mmap(),去从内核那边获取虚拟内存。堆管理代码中的malloc(),通过重用被free的内存块,来满足用户对于堆存储的请求。
实际上,malloc的实现包含了mmap以及其他系统调用以用于扩大用户堆存储的大小。因此我们可以这样理解:malloc实际上是更多对于内存的重用,以减少碎片,而mmap实际上是从操作系统获取这块内存。
现在有个问题:既然虚拟内存这么多,为什么我们不一直使用mmap而是使用malloc呢?
因为可能我是想去重用内存,而不是一直去申请新的内存。如果我一直使用mmap,那么我就会一直去申请新的内存,这样会导致内存碎片。
对于大粒度的内存分配,mmap()是一个很好的选择,但是对于小粒度的内存分配,malloc()是一个更好的选择。
回顾地址转换
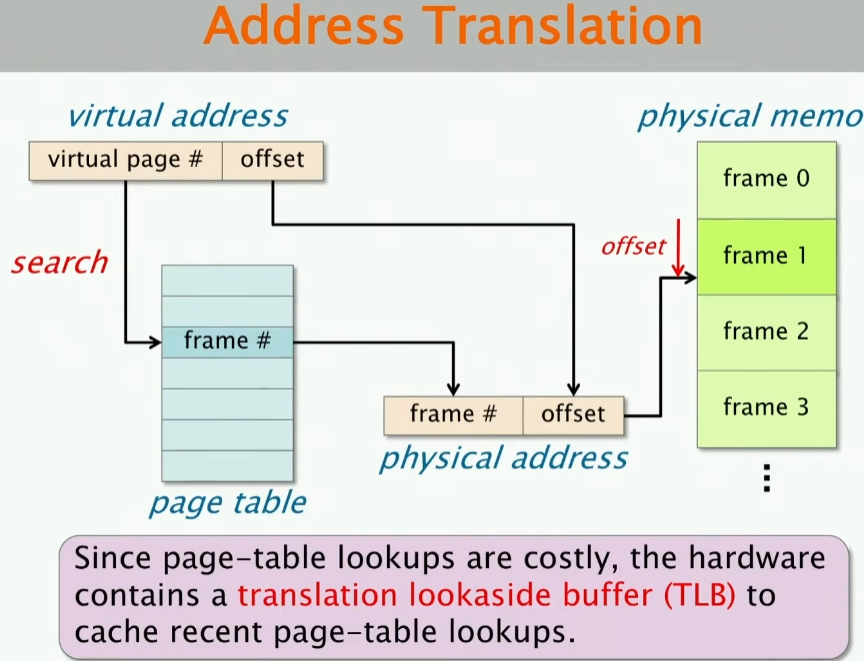
有个问题:什么会使得TLB大量命中呢?
如果你写的程序有很好的空间局部性或时间局部性或两者,那么你的TLB就会有很好的命中率。
栈实现
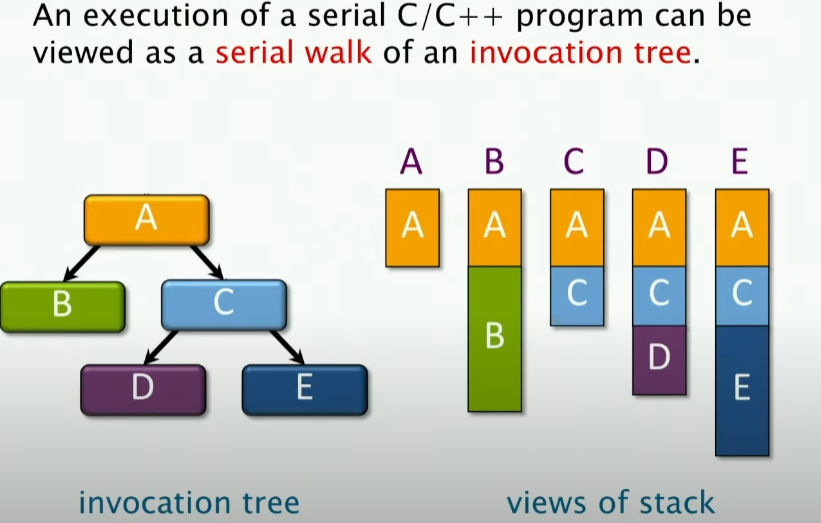
上述图是一个调用树,在C/C++中,调用树实际上对于串行程序来说,可以被看成是一个串行的walk。就上述图而言,我们最初调用A的时候,我们有一个A的栈帧,然后我们调用B,我们有一个B的栈帧,此时我们返回,再调用C,其结果如上图所示。
好了,上述会涉及一个重要的问题,从上图的角度来看,为什么子级的局部变量不能给父级?
这涉及一个overwritten的问题,这里有一个关于指针的问题,父级可以通过指针访问子级的局部变量,但是子级不能通过指针访问父级的局部变量。当我在B中将其局部变量指针给A,但是当A去调用C的时候,C会覆盖B的局部变量,如果C覆盖的区域和B的局部变量区域重叠,那么B的局部变量就会被覆盖。
那么如果我们想将内存从子进程传递回父进程,那么我们该在哪分配呢?
有两种方法:
- 我们可以把这块内存分配给父进程栈空间
- 子代在堆上面分配它
现在的许多C函数都要求你分配内存去存储返回值,实际上就是尽量去避免子代中昂贵的堆分配。因为,如果父进程分配此空间用来存储结果,那么子进程只需要将计算的任何结果指向这个空间,然后父进程就可以访问这个结果。因此,**父级是有责任去确认是否在栈上面还是在堆上面分配内存。**这也是为啥你看到很多C语言的参数,其中之一是用来存储结果的。(也可以理解为局部内的变量,存储子级的返回值)
那么如果是并行的情况呢?
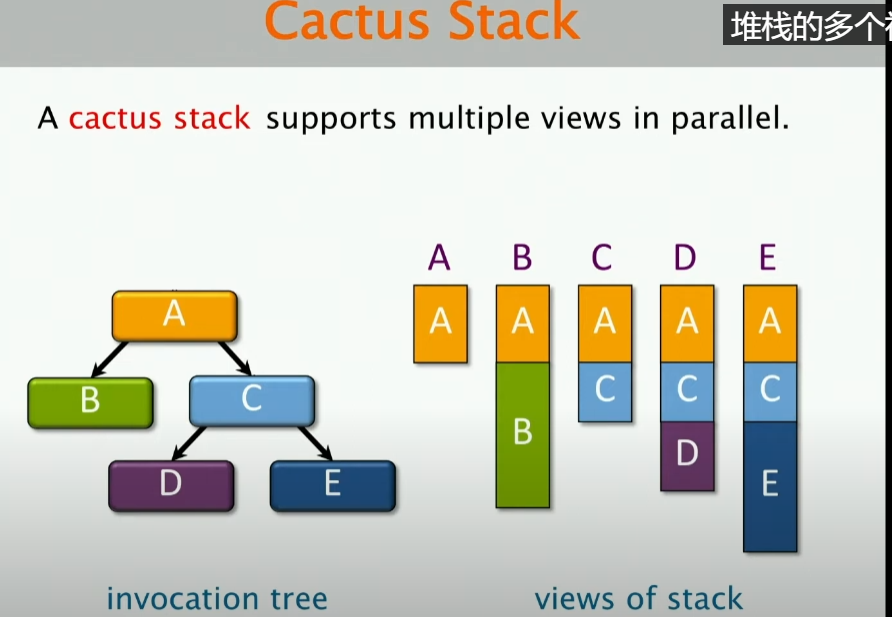
如果是并行的情况,那么这样会有很多关于栈的视图,对于这些并行的视图,特别对于A的内存区域,具体实现的情况下,我们看到的都是同一块虚拟内存区域。那么,我们应该如何去实现呢?
当然是Heap!做Heap-Based Cactus Stack!
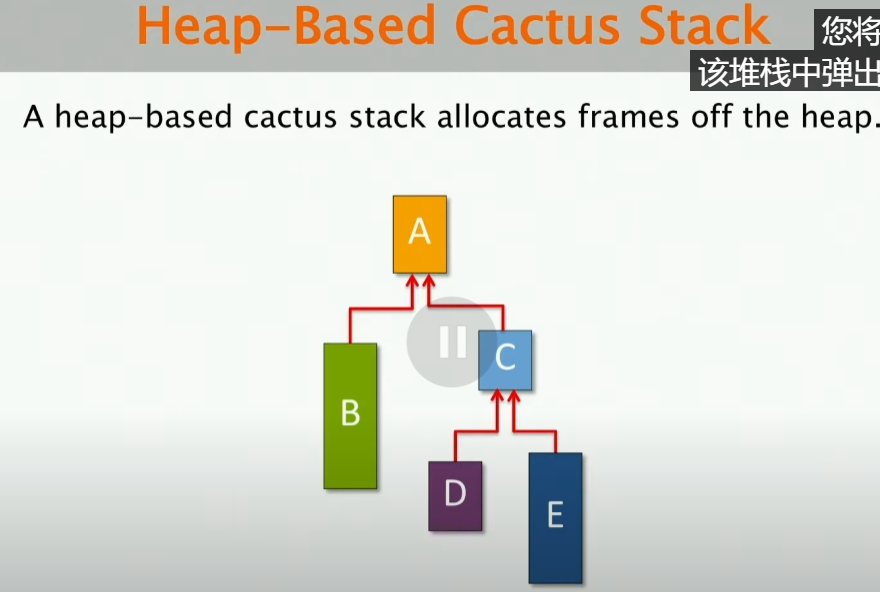
这里每一个栈帧都有一个指向父级的指针,当你进行函数调用的时候,都会从堆中分配一个新的栈帧,然后将其指向父级的指针指向父级的栈帧。
但是上述实现方法有一个问题!
所以,当我尝试将heap-based cactus stack与常规的栈程序一起来运行某些程序的时候,会发生什么?我们假设这里有一个使用传统的线性栈编译的遗留的代码,由于线性栈的特性,其会认为你的调用是紧接在它之后的,但是实际上,你的调用是在堆上面的,这样就会导致一些互操作的问题。(即使我重新编译代码,将这些都用成heap-based,但是仍然会有一些栈操作,因为系统是认为你的这些函数调用是在栈上面实现的)
space bound of cactus stack
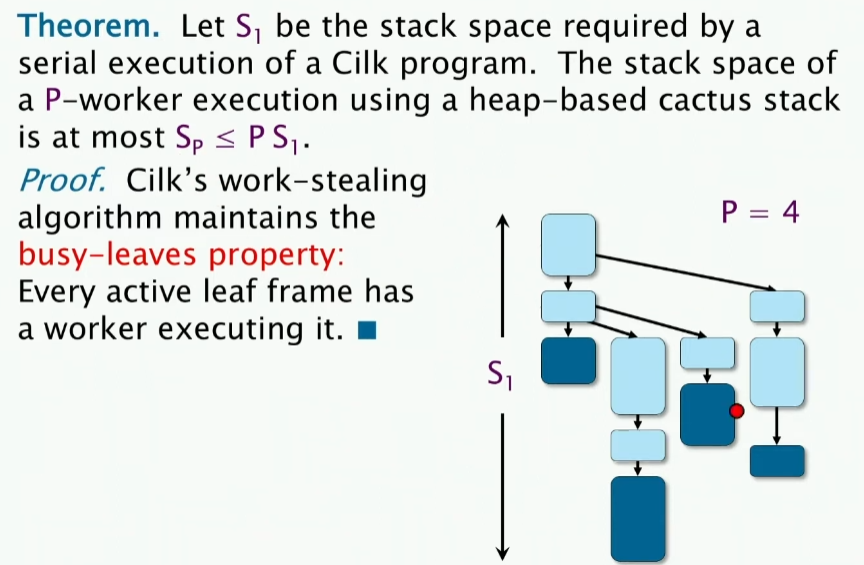
这个很容易理解。不做过多解释了
D&C Matrix Muliplication
我们重新去看这个分支递归的矩阵乘法,我们这次关注的是这段代码的space

我们首先回顾一下这个函数的work 和 span
- work:
- span:
- space:
work:
span:这里对于右边是加上加法的span,也就是分治后合并的开销,这里为什么不乘以8呢?因为这里是并行的,所以不需要乘以8。下表是inf即表示有无穷多个处理器,这里是并行的,所以不需要乘以8。
这样,我们查表,就可以得到span的结果。
(,即k=1,那么结果就是上述了)

同时,这里的space如下:
实际上,我们在分配空间的时候,是递归的时候,但是我们真的需要8个这样的递归吗?当我们完成某个任务的时候,我们释放了这个空间,我们可以重用它,因此我们只需要的空间即可:[这里的S(n)代表递归空间,n平方即矩阵空间大小]
存储分配的基本属性
分配器速度,即分配器可以维持的每秒分配和释放的次数
现在有一个问题:我们在对分配器做优化的时候,要求最大化分配器速度,但是优化的重点是优化对于大的block的速度还是小的block的速度?
——答案是优化小的blocks,因为:
- 对小块进行的分配要比大块更加频繁
- 通常,一个用户程序对于一个块的操作,大块所占用的读写时间要比分配器的分配时间多得多,所以整体看来,分配器的时间在整个的运行时间上面有着很小的影响。相反,如果一个程序分配了很多的小的blocks,那么分配器的分配时间可以作为一个重要的开销。因此,本质上,我们对于大块可以分摊存储分配的开销。
我们继续引入定义:
我们定义fragmentation(碎片化):用户占用空间(user footprint)是指最大的用户程序使用的字节数 U (用户程序占用字节数随时间变化的最大值,是已分配但是未释放的字节),分配器占用空间是指由操作系统所分配的最大使用字节数A。我们就定义 fragmentation=F=A/U
blowup:指的是对于并行的分配器,其需要的分配空间要比串行分配器多多少(一般是比值)
并行分配策略
策略1:全局堆、global heaps
所有的线程都共享一个堆空间,通过锁机制实现原子性。
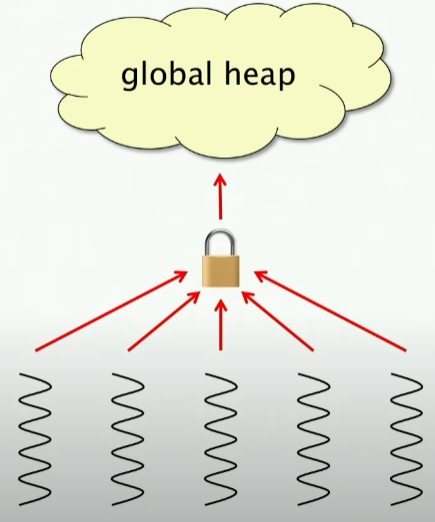
这里的:
- blowup=1,我只维护一个全局堆
- 但是很慢,因为每次分配都需要加锁,这样就会导致很多的线程都在等待锁,这样就会导致很慢,你需要去支付类似L2-cache access的时间。
- 由于随着线程数目增大,竞争会非常激烈,导致其可扩展性很差
策略2:local heaps
每个线程都去维护自己的堆空间,不需要加锁。每个线程都将从自己的堆中去进行分配工作:
- 很快,不需要同步工作
- 但是blowup很大,因为每个线程都需要维护自己的堆,这样就会导致很多的空间浪费,除了对于内存消耗大之外,还有一个现象为内存漂移,即一个线程申请了很多很多空间,但是另一个线程去释放这个空间了,这就叫内存漂移。本质上来说就是分配器不够智能,不知道重用其他线程的空间。
(其实操作系统只知道给分配器这些空间,到底怎么做并行还是看分配器,本质上local heaps看起来是各自用各自的,但是空间还是需要申请和释放的,这就变相带来了所谓的共享)
策略3
针对策略2出现的问题,这里有了策略三,即释放的时候,释放回分配它的线程。
每一个object都被标记为属于哪个线程,当一个线程释放一个object的时候,这个object就会被释放回给这个线程。
 wechat
wechat alipay
alipay