
性能优化学习笔记6
多核编程
这里的引言就是随着摩尔定律的终结,单核处理器的性能提升已经非常有限,而多核处理器的出现为我们提供了一种新的性能提升途径。多核处理器的出现,使得我们可以通过并行的方式来提高程序的性能,但是多核编程也带来了一些新的问题,比如线程之间的通信、数据共享、数据一致性等问题。本文将介绍多核编程的一些基本概念和技术,希望对大家有所帮助。
这门课学到的一个单词组:Argument Marshelling 就是说将参数打包成一个结构体,然后传递给函数。(参数编组)
Shared-Memory Hardware
Cache Coherence(缓存一致性)
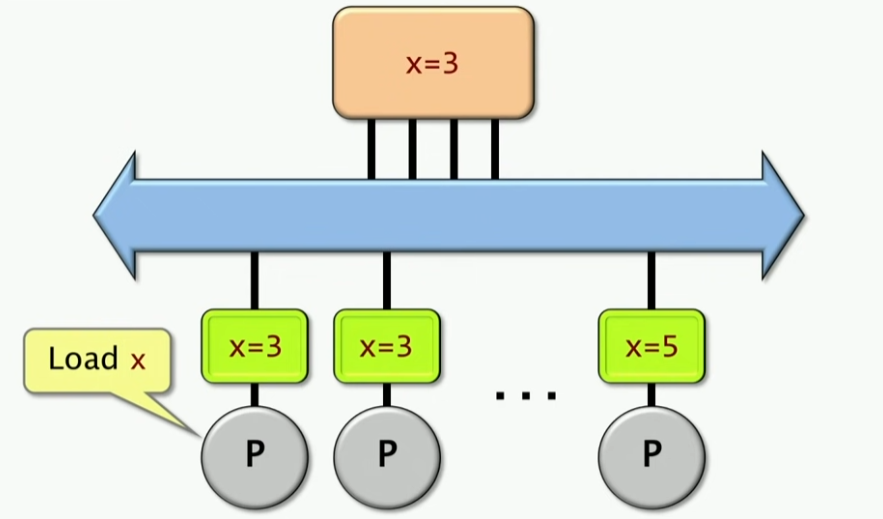
现在有一个x=3在主存里面,这里有多个处理器,处理器想要获取x的值,要把x的值加载到自己的缓存里面,这个时候就会出现缓存一致性的问题,比如处理器1把x的值加载到自己的缓存里面,然后处理器2也把x的值加载到自己的缓存里面,这个时候处理器1修改了x的值,这个时候处理器2的缓存里面的x的值就是过期的,这个时候就会出现缓存一致性的问题。
值得注意的是,如果某个处理器想要获取这个x的值,它可以通过从其它处理器的缓存中获取,这样会更快一点。
这里有一个问题在于,最后一个处理器修改了x的值,这个时候x的值在其它处理器的缓存里面是过期的,这个时候就需要处理器1去主存里面获取x的值,这个时候就会出现性能问题。因此,多核的第一个重要问题就是缓存一致性问题,确保多个处理器的缓存里面的数据是一致的。
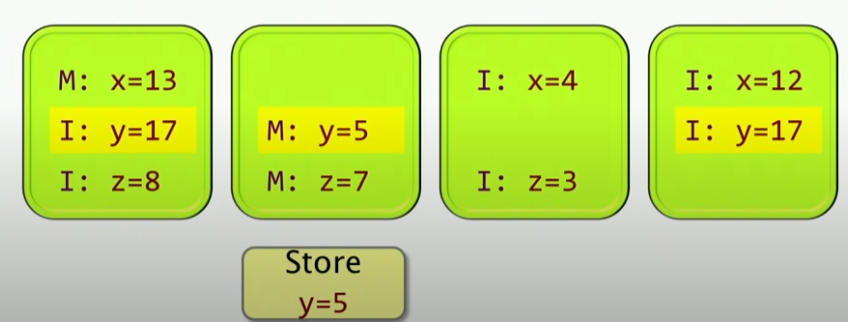
这样,就有一个解决该问题的基本协议:MSI协议,其核心思想就是:每一个Cache line都是被标记为一种状态,这里有三种状态:
- M:Modified,表示这个Cache line是被修改的,这个时候这个Cache line是独占的,其它处理器不能访问这个Cache line。
- S:Shared,表示这个Cache line是共享的,这个时候这个Cache line是可以被其它处理器访问的。
- I:Invalid,表示这个Cache line是无效的,这个时候这个Cache line是无效的,其它处理器不能访问这个Cache line。
目前Cache line的大小主要是64字节。

如果一个处理器想要更改y的值,比如第二个处理器想设置y=5,那么对应处理器的Cache line就会变成M状态,这个时候其它处理器的Cache line就会变成I状态,这个时候其它处理器就不能访问这个Cache line了。如下所示:
Concurrency Platforms(并发平台)
为什么要有并发平台?因为多核编程是一个非常复杂的问题,我们需要一些工具来帮助我们解决这个问题,这就是并发平台的作用。一个并发的平台,抽象出了多个处理器之间的同步、通信协调以及提供负载均衡等等。
Fibonacci Program
1 |
|
这样的递归程序实际上是一个非常低效的程序,这个程序消耗的时间是指数级的。其实有更好的方法去计算斐波拉契数列,有一种方法使用线性的时间复杂度,即自下而上计算斐波那契数列/动态规划的方法。还有一种方法去计算斐波那契数列,花费log级别的时间复杂度,即基于平方矩阵的方法。
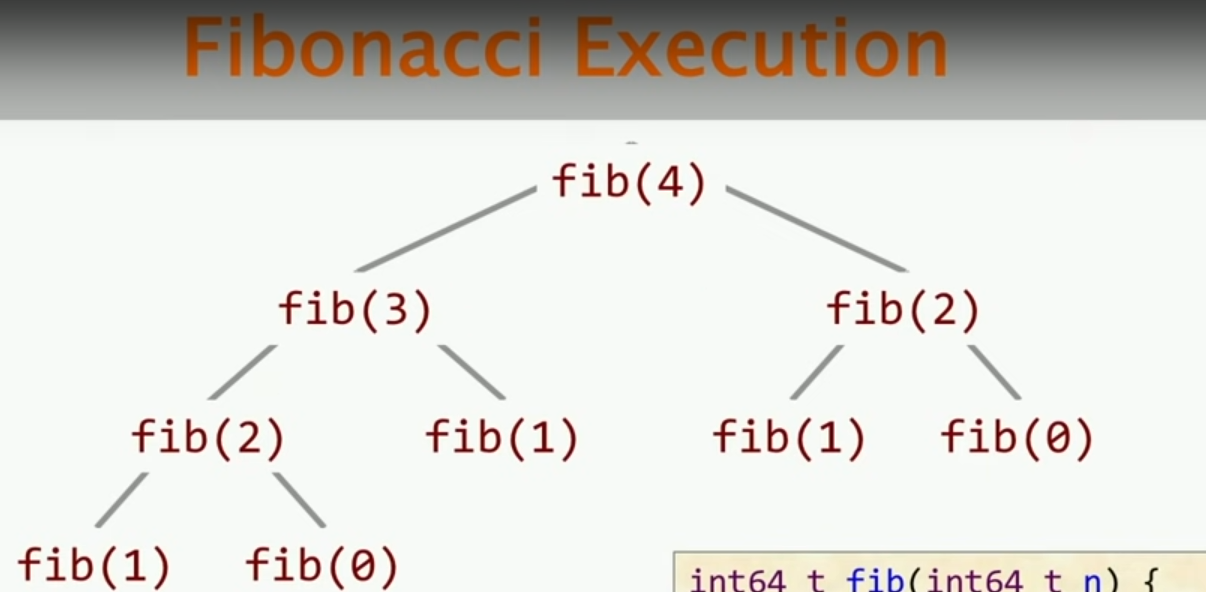
如果我们关注fib函数的计算过程,我们可以发现,上述图中,fib(2)被重复计算了多次。实际上并行计算的核心思想在于我们可以同时去计算fib的两个递归子调用,并且这种并行也是可以递归的。这样的并行计算的核心思想就是:分治。
Pthreads
我们来看我们是怎么使用Pthreads去实现这个简单的斐波那契数列的。
Pthreads是一种标准的API,去处理多线程的问题。其被构建为一种C语言的库,其提供了一些函数去创建线程、同步线程、销毁线程等等。每一个线程都实现了处理器的抽象。然后这些资源被复用到实际的机器资源上面。
Key Pthread Functions
1 | int pthread_create( |
接下来是关于用Pthread去实现斐波拉契数列:
1 |
|
上述有一点要注意的是,关于指针函数,传入的参数为 Void * 的指针,其实这是一种泛型指针,可以指向任何类型的指针,这样的好处是可以传入任何类型的指针,但是在使用的时候需要进行类型转换。
上述代码中,一共进行了两个并行,也就是说,如果我有四个处理器,那么运行速度只有两倍,因为只有两个并行。这样的并行是有限制的,因为我们的这种并行只在顶层创建线程,并没有递归地去做。如果我想递归地创造线程,实际上代码会更加复杂。
Threading Building Blocks
这是一个Intel公司开发的一个并行编程库,其提供了一些高级的抽象,比如并行循环、并行任务等等。其被实现为一个C++的库,其提供了一些类和函数去实现并行编程。这个库的核心思想是:任务并行。(编程人员具体是以任务为划分,而不是线程)这些任务使用工作窃取的算法去在线程之间自动进行负载均衡。
TBB更多的是关注性能,其写出来的代码要比Thread更简单,接下来我们来看用TBB写的斐波拉契数列的代码:
1 | using namespace tbb; |
1 |
|
用TBB写的代码能够获得更高的并行性。同时,TBB还有很多其它的性能:
- 并行循环:tbb::parallel_for
- 并行减少:tbb::parallel_reduce,用于数据聚合,比如你想要并行计算一个数组的和
- 管道和过滤器:用于软件流水线的并行计算
同时,TBB还提供了各种并发的容器类,可以允许多个线程去安全地、并行地更新、修改容器中的item,比如有一个并发的队列、并发的哈希表等等。
OpenMP
OpenMP实际上是一种业界标准,有多种编译器都支持OpenMP,比如GCC、Intel C++ Compiler、Clang等等。实际上,我们可以通过在代码中使用一些编译器编译指示来指定哪些部分代码是并行的,这样编译器就会自动地去并行化这些代码。OpenMP支持循环并行、任务并行以及流水线并行。
1 | // Fibonacci in OpenMP |
上面代码中,# 开头的语句,我们称为Compiler directive 也叫编译器指令,用于创建并行任务的指示为: #pragma omp task。这样的指示告诉编译器,这个任务是并行的,编译器会自动地去并行化这个任务。这样的指示可以用于循环并行、任务并行以及流水线并行。上述代码中,对于shared这个关键字,表示两个变量在不同线程中是共享的。
Cilk Plus
Cilk是C/C++的一种扩展,其提供了一些关键字去实现并行编程。Cilk Plus是Intel公司开发的一种并行编程的扩展,其提供了一些关键字去实现并行编程。Cilk Plus提供了一种更加高级的抽象,比如并行循环、并行任务等等。而对于Cilk Plus中的Plus部分,主要是支持矢量的并行。
1 | // cilk code for Fibonacci |
上述代码中,我们只使用了两个语句,一个cilk_spawn 和 cilk_sync。cilk_spawn表示其后面的子函数可以与父调用者并行进行,可以,cilk_sync表示所有的生成的子级返回之前,控制无法通过此节点。
值得注意的是,cilk_spawn只是一个提示,编译器可以选择是否并行执行这个任务,这样的好处是编译器可以根据实际情况去选择是否并行执行这个任务。实时运行系统可以根据实际情况去选择是否并行执行这个任务。
Loop Parallelism in Clik
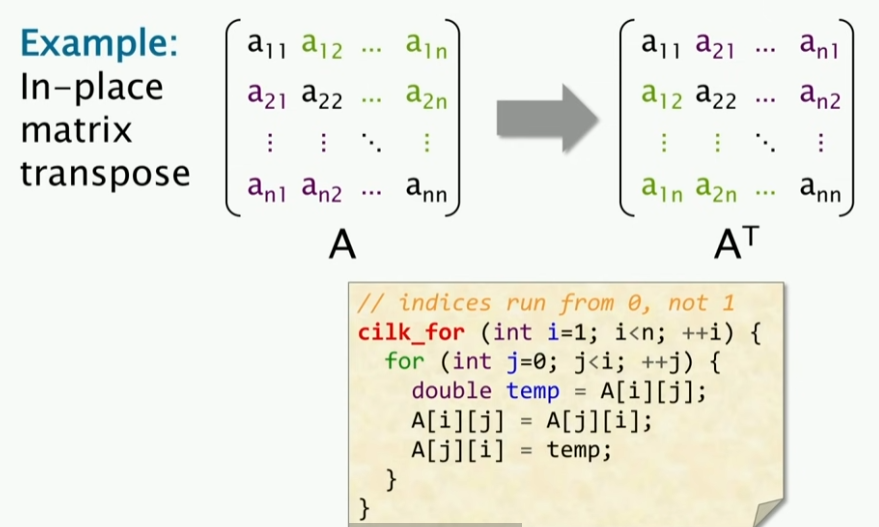
现在我有一个任务,就是把矩阵对角线的数据进行交换,即做转置运算。这个时候,我们可以使用循环并行去实现这个任务。这个时候,我们可以使用Cilk Plus的关键字cilk_for去实现这个任务。
1 | cilk_for(int i=1; i<n; ++i){ |
实际上,对于编译器来说,会去掉cilk_for,然后在内部使用嵌套(nested)的cilk_spwan和cilk_sync。也就是说,不同的迭代是并行的。
Reducers in Cilk(Cilk中的规约)
我们来看一个并行求和的例子:
1 | unsigned long sum = 0; |
首先,第一种最直接的方法就是尝试把for换成cilk_for,代码如下:
1 | unsigned long sum = 0; |
很明显,如果我们对于规约性质的工作也是这样去做并行优化,明显没有用,因为这里的每一次迭代是有关系的。甚至使用这样的cilk_for不一定会给你正确的答案。核心思想就是,这里存在:确定性竞争,即多个处理器可以写入同一内存位置。
下面是一个优化示例,使用了超对象(hyper object)以及Cilk中的规约器(Reducer),我们用一个宏去定义这个sum变量,其具有特殊的加法函数,我们通过宏来定义:
1 | CILK_C_REDUCER_OPADD(sum, unsigned long, 0); // 通过宏构建具有加法函数的对象 |
 wechat
wechat alipay
alipay