
性能优化学习笔记5
C to Assembly
早在大四上学期之前,我就有看《程序员的自我修养》这本书的想法,可惜到后面也没有坚持看完,感觉那本书很难啃,而今天这门课也是关于这方面的内容,看来还是逃不掉啊,哈哈哈 💀
Clang/LLVM Compliation Pipeline
- 首先进行预处理,处理所有的宏定义,包含头文件等等,生成一个
.i文件 - 生成中间代码,LLVM IR,生成一个
.ll文件,其中IR表示Intermediate Representation - 生成汇编代码,生成一个
.s文件
我们可以通过查看中间表示来得知编译器做了哪些东西,这样我们就可以更好的理解编译器的工作原理。
LLVM IR PRIMER
LLVM IR 的指令格式很简单,其格式为: [destination] = [operation] [operands]
其控制流是通过条件和非条件跳转来实现的。
特别需要注意的一点是:LLVM IR有无穷多的寄存器,这样就不需要考虑寄存器的分配问题,这样就可以更好的优化代码。这样当我们在看其代码的时候,我们就把这些寄存器当作C语言中的变量来看待。
LLVM IR Registers
- 比如
%0: 代表一个寄存器,通过%[name]来表示,就像C语言中的变量一样 - 寄存器名字对于每一个LLVM IR的函数来说都是local的,也就是说不会有全局寄存器,比如说有两个函数,他们的寄存器名字是一样的,但是他们是不会冲突的,因为他们是local的。
LLVM IR Instructions
用指令创建一个值的语法如下:
%[name] = [opcode] [operand list]
其他指令的语法如下:
[opcode] [operand list]
operands是一个逗号分隔的寄存器列表、常量或者“basic blocks”
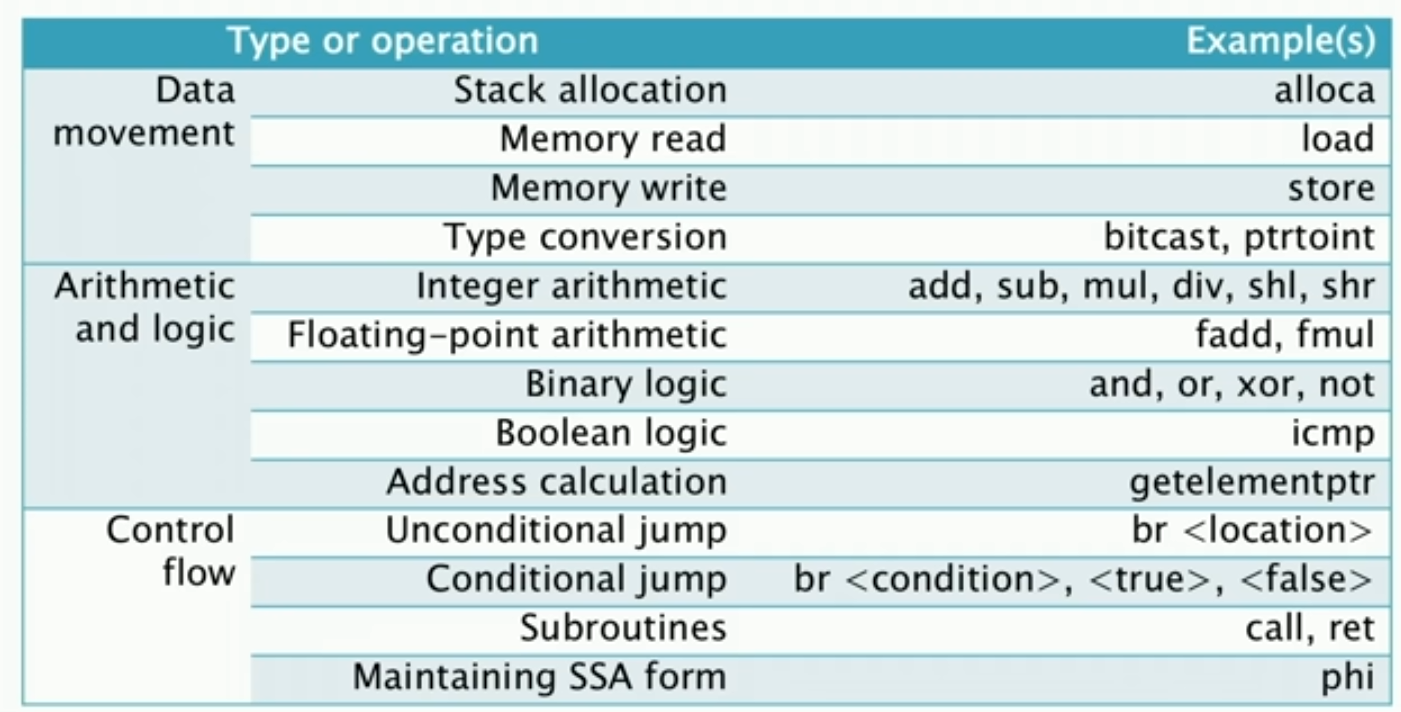
上图为LLVM IR的一些指令。
C to LLVM IR
Straight-line C Code in LLVM IR
首先,对于Straight-line C Code的定义是:没有分支的C代码,也就是说没有if、while等等的语句。
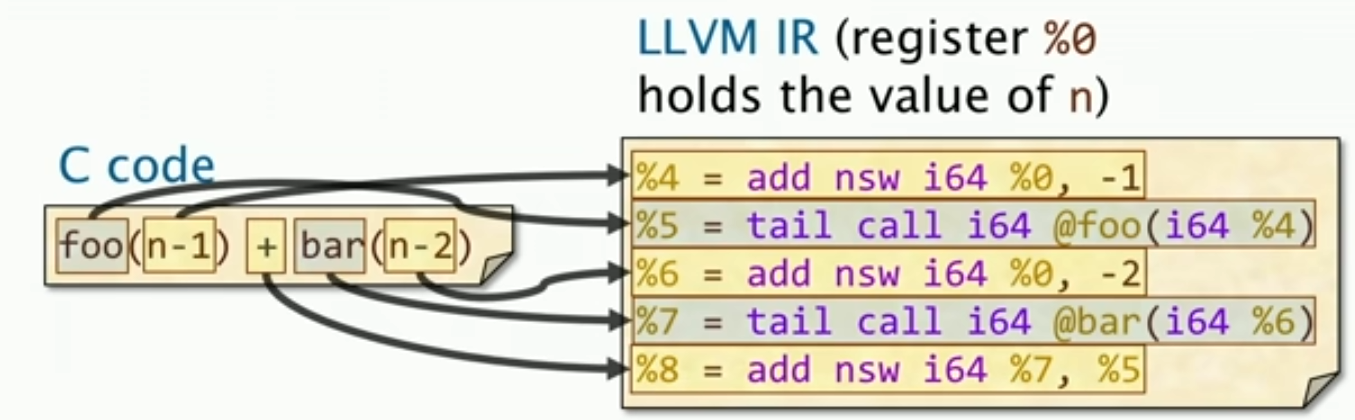
对于LLVM IR指令,这里有两大特点:
- 所有的参数在进行C操作之前,都会被evaluated,也就是说在进行操作之前,所有的参数都会被计算出来。
- Intermediate结果,即中间结果,会被存储在一个新的寄存器中,这样就可以避免重复计算。
Aggregate Types
除了原始的数据类型之外,LLVM IR还支持一些聚合类型,比如数组、结构体等等。
对于聚合数据,寄存器一般很难去存储,所以这些类型的数据一般存在内存里面,因此想要获取数据需要涉及访存操作。

这里有一个简单的例子,我们首先计算一个地址放在寄存器里面,然后执行load指令,将这个地址的值加载到寄存器中。这样我们就获取了A[x]的值。
The getelementptr Instruction
这个指令是用来计算聚合数据的地址的,比如说结构体、数组等等。
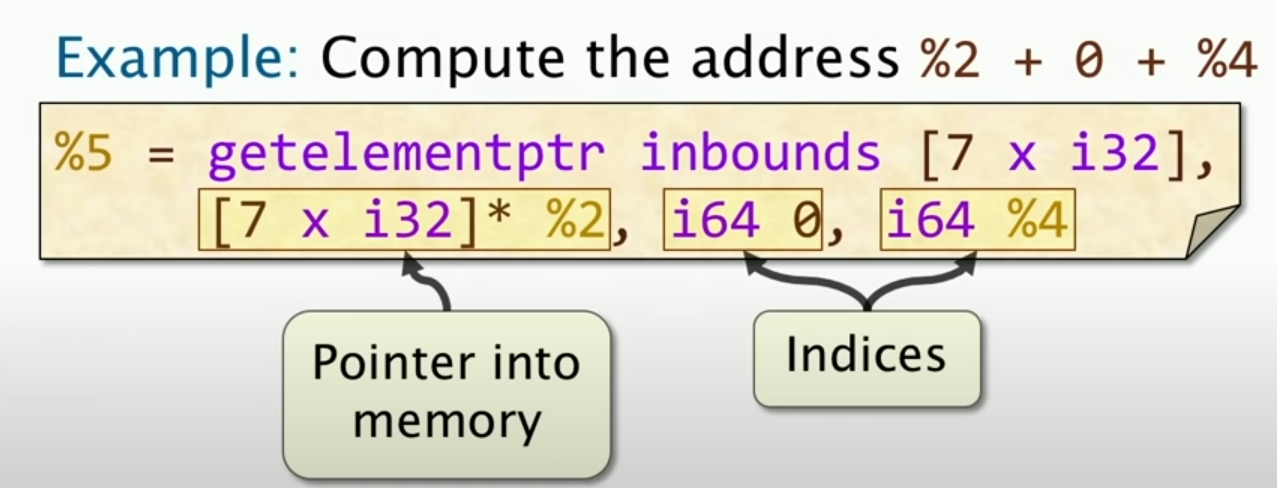
实际上,这条指令就是在计算这个数组,从2开始,加上两个偏移量,一个是0,一个是寄存器4的内容,然后将结果存储在寄存器5中。
C 函数到LLVM IR
标题都是英文有点不顺眼,哈哈哈
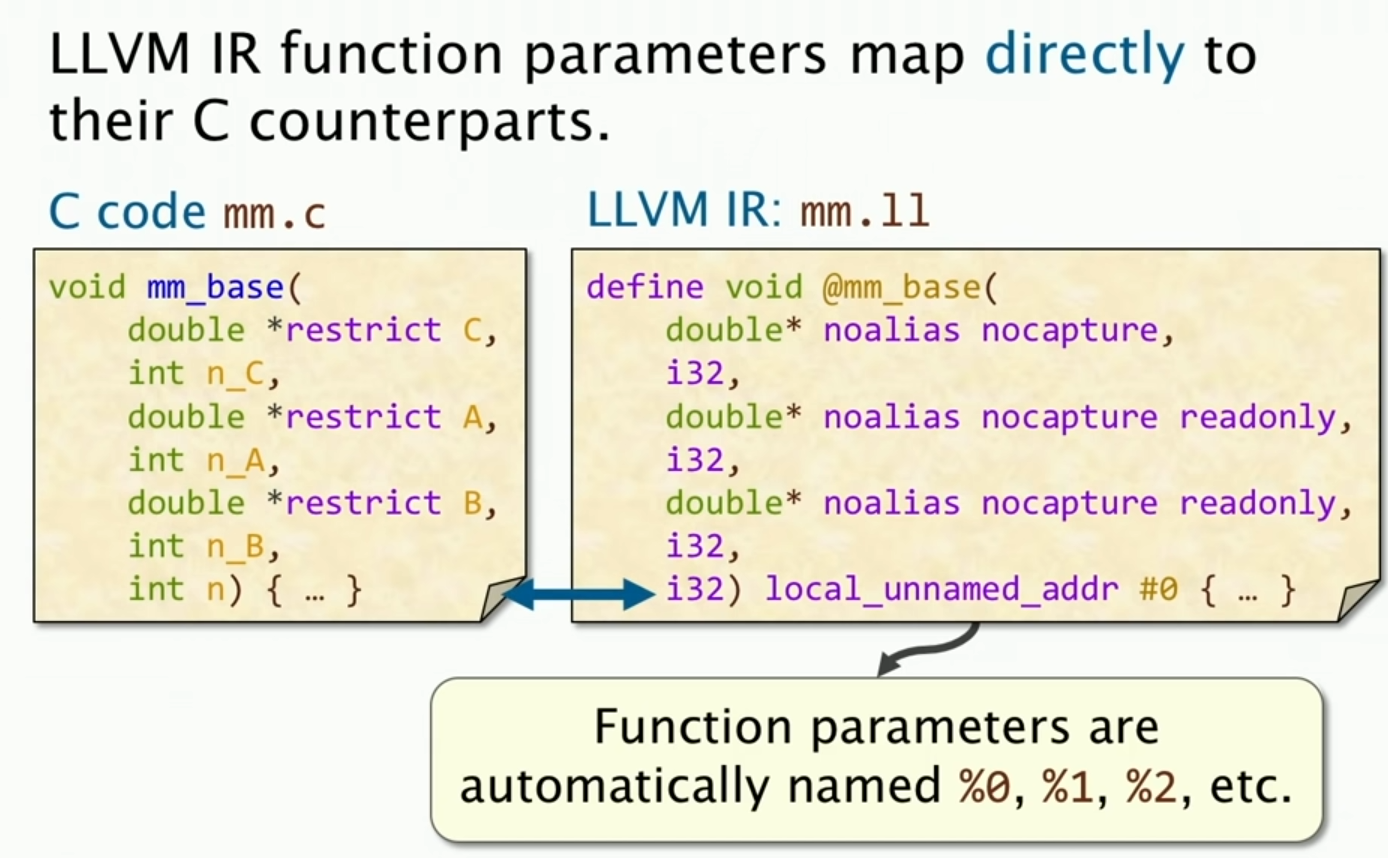
我们首先来看参数对应的映射,基本上没什么区别,值得注意的是,有一个隐式的定义,函数的参数会被自动命名为%0、%1、%2等等。
然后是对于基本块,基本块的定义就是,一个基本块是一个连续的指令序列,其中只有一个入口和一个出口,这样就可以保证控制流的一致性。其中对于入口,仅仅从块的第一条指令开始,而对于出口,仅仅从块的最后一条指令结束。(下图显示了三条分支,写成了三个块)
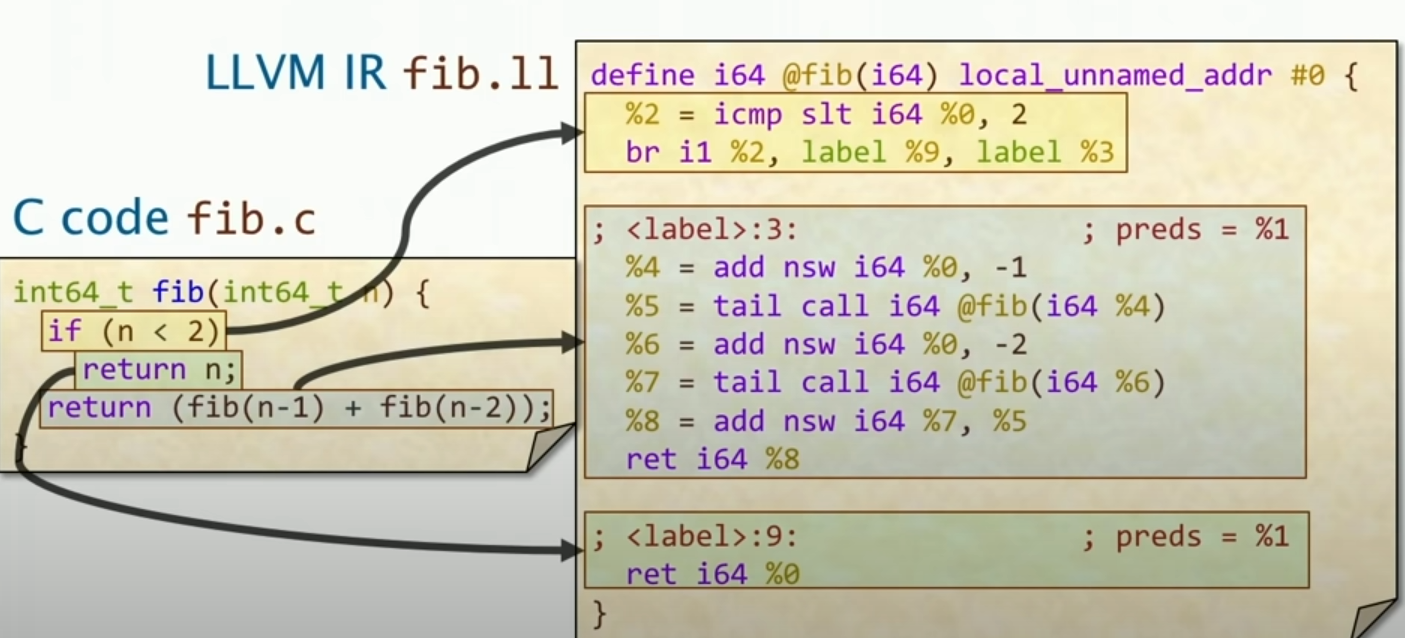
Unconditional Branches
我们之前看到的条件转移分支,在LLVM IR中,也有无条件转移分支,这个指令是br。我们可以从上图观察得到。
接下来我们看无条件的分支:

这样写看起来有点笨,为什么我们不直接把要跳转到的块merge在一起呢?因为这是为了防止其他事情进入这个块,这样就可以保证这个块只有一个入口和一个出口。例子如下:
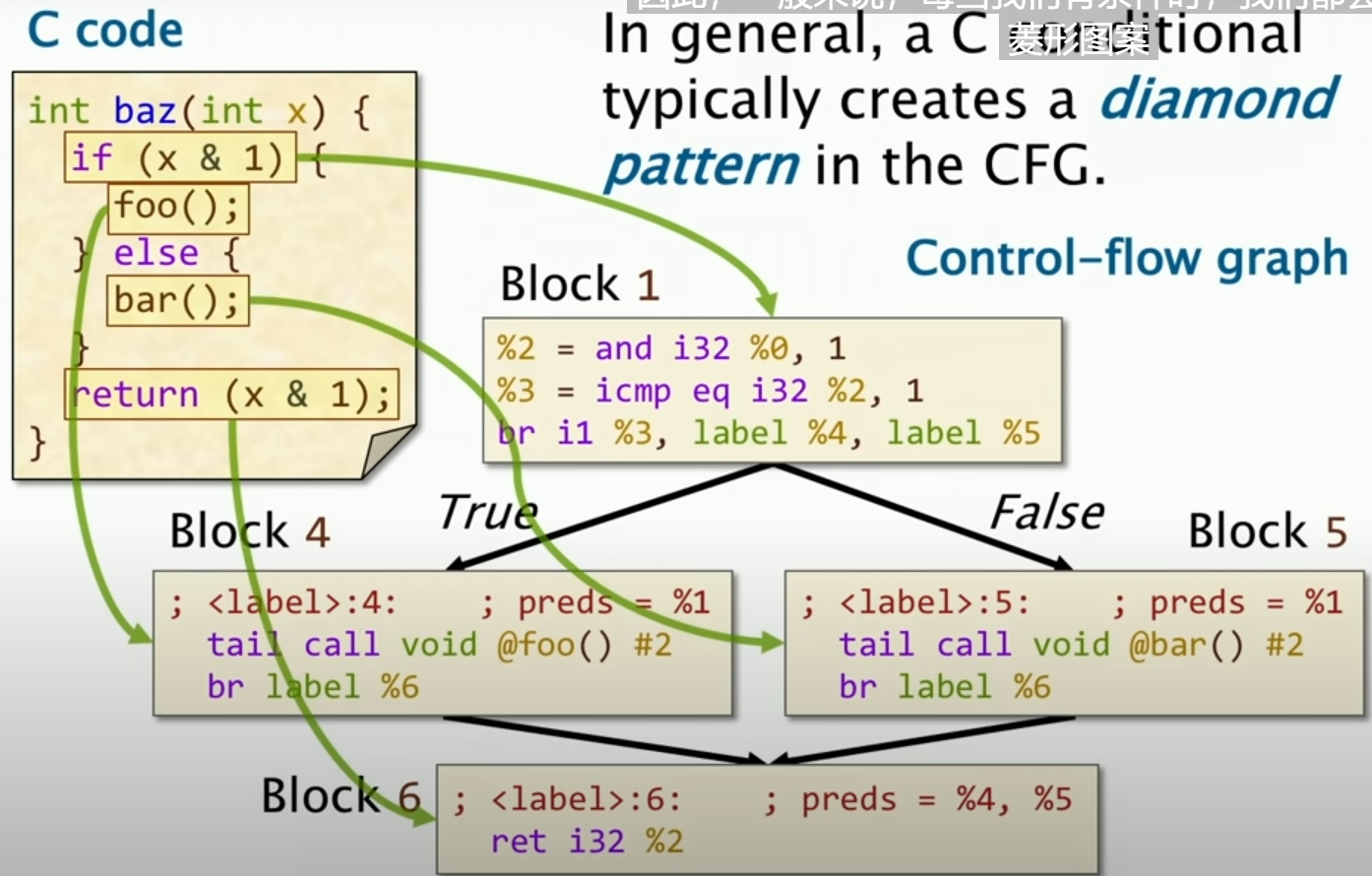
C循环到LLVM IR
对于循环,实际上要解决的问题在于对于变量i的递增,
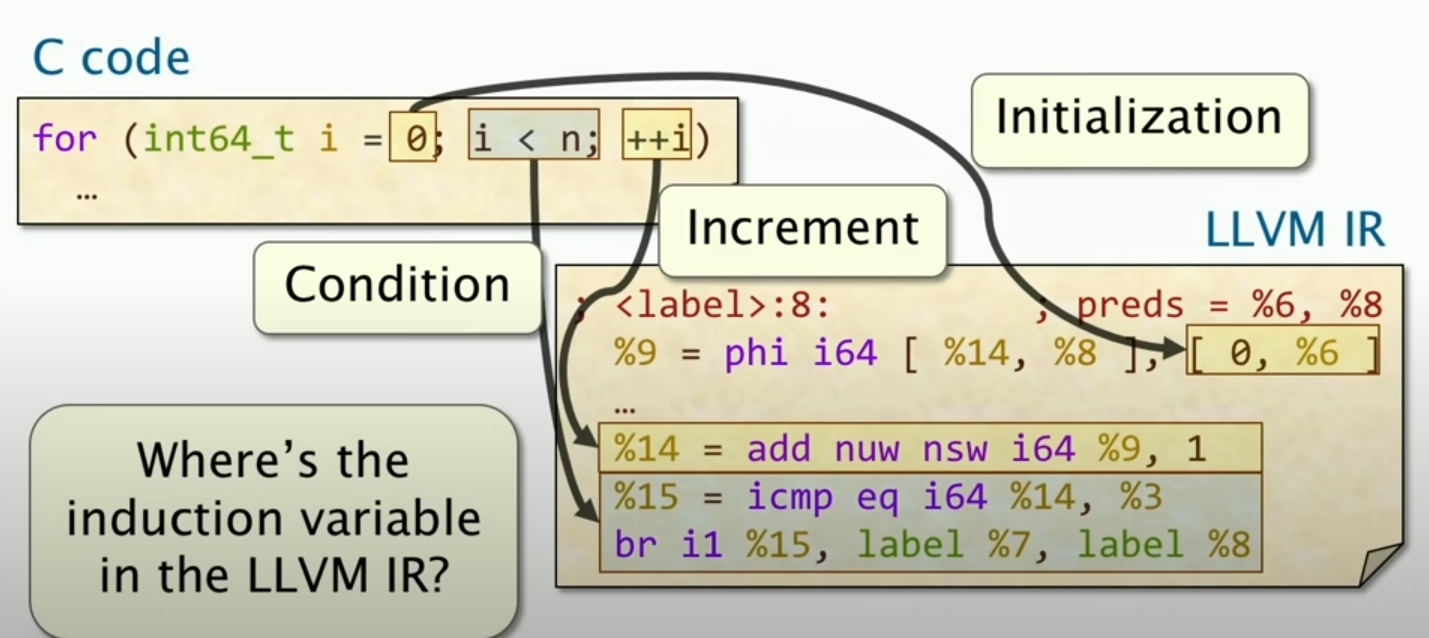
这里的phi指令就是去解决这个问题的,phi指令的作用是根据控制流的不同,选择不同的值。我们可以看到,在循环里面,有一个递增的值,这个值就是phi指令的作用。具体而言,如果初始化i=0的时候,那么i的值就是0,如果是在循环里面,那么要先进行递增操作(increment)。同时,我们可以看见,在做递增的时候,要改变寄存器,因为循环会改变寄存器的值。所以我们可以看到首先%9 = phi i64是存储了i的值,然后%14 = add nuw nsw i64 %9, 1,这个就是递增操作,这个就是改变寄存器的值。
Calling Convention
程序在运行的时候在内存中的布局
当程序执行的时候,虚拟内存会被分为多个段,首先有一个段对应于栈,**其中栈是向下增长的。同时也有一个heap,这个段是向上增长的。**因此这两个部分实际上是动态分配的,而对于代码段和数据段,这两个段是静态分配的,因此这两个段是不会变化的。在虚拟空间的底部,是代码段。
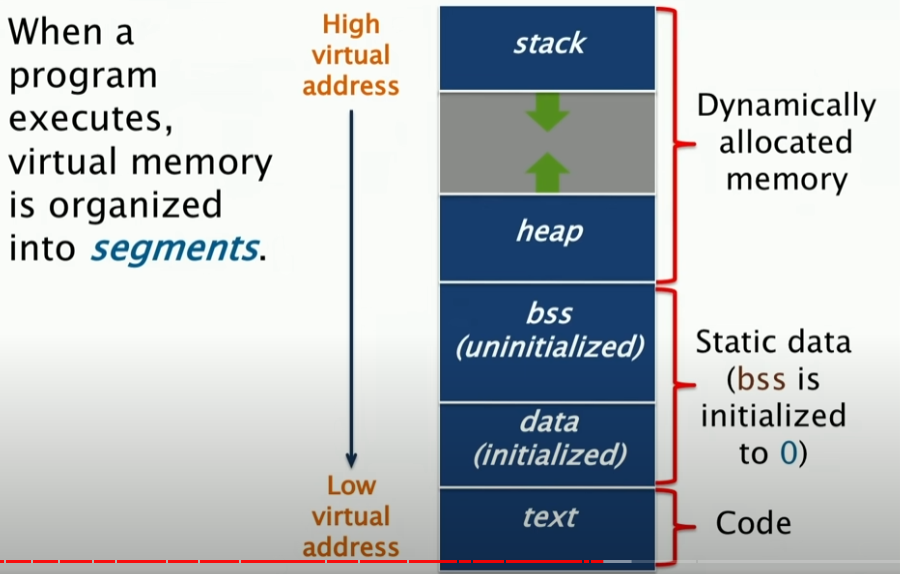
我们首先来讲stack段,这个栈段存储的是与函数调用和返回相关的数据。那么,我们问什么需要这个栈呢?哪些数据最终会到达那里?
局部变量、函数参数、返回地址、寄存器状态[保证不同的函数去使用相同的寄存器]
现在有一个问题:
我想要把不同的目标文件以及库里面的函数自由地相互调用?我应该怎么去协调栈和寄存器?
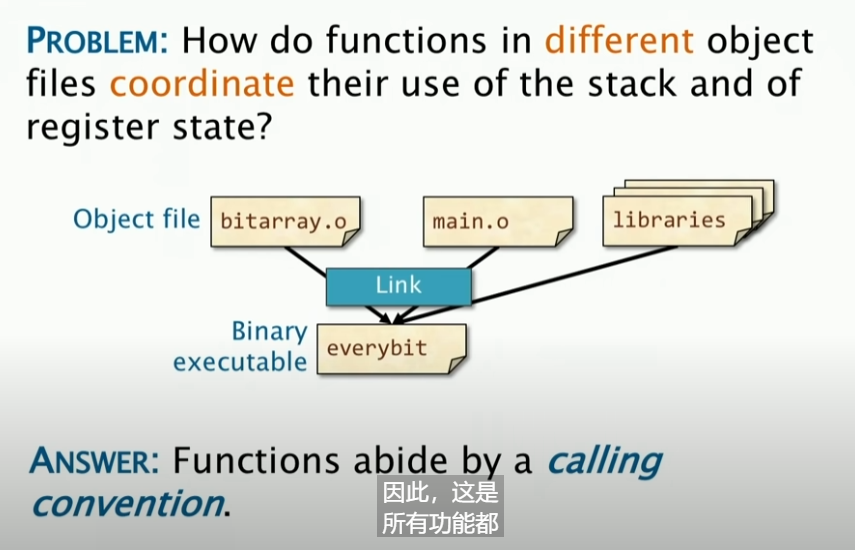
Linux x86-64 Calling Convention
从一个高层次的角度来看,答案为:**所有的函数都遵循同一套规则,这套规则就是calling convention。**接下来我们去讲解这个Calling Convention在Linux系统里面的实现:
Linux系统里面实际上是把栈组织成一个栈帧,这个栈帧是由函数调用者来创建的,然后由函数调用者来销毁。每一个函数的实例都有一个栈帧,这个栈帧包含了函数的参数、局部变量、返回地址等等。关于栈帧有两个属性,%rbp和%rsp,%rbp是指向栈帧顶部,而%rsp是指向栈帧底部(栈向下增长)。%rip是指令指针,是针对call和ret指令的。这个%rip是用于管理函数的返回地址的。当我们使用Call指令的时候,就把%rip的值压入栈中,然后跳转到函数的地址。当我们使用ret指令的时候,就把栈顶的值pop出来,然后跳转到这个地址,并且回到调用者,恢复之前的语句执行。

在不同的Call中维护寄存器
在函数调用,即A调用B的过程中,谁来负责保存这个寄存器的状态呢?如果让A来维护,那么可能会引起一堆浪费的工作,也就是说,可能B并没有用同一个寄存器;如果让B来维护,同样的道理,可能A并没有用同一个寄存器。所以我们需要一个统一的规则来维护这个寄存器的状态。
所以,不管是谁来全权负责,都有可能造成这样的状态:我不管对方是不是需要,我都保存当前寄存器状态,把一堆东西往堆栈里面放
答案是:Linux x86-64对上述两种情况都有考虑,有一部分是由被调用者来维护(%rbx, %rbp, %r12-%r15),有一部分是由调用者来维护(other registers)。
Linux C Subroutine Linkage(Linux C 语言子程序链接)
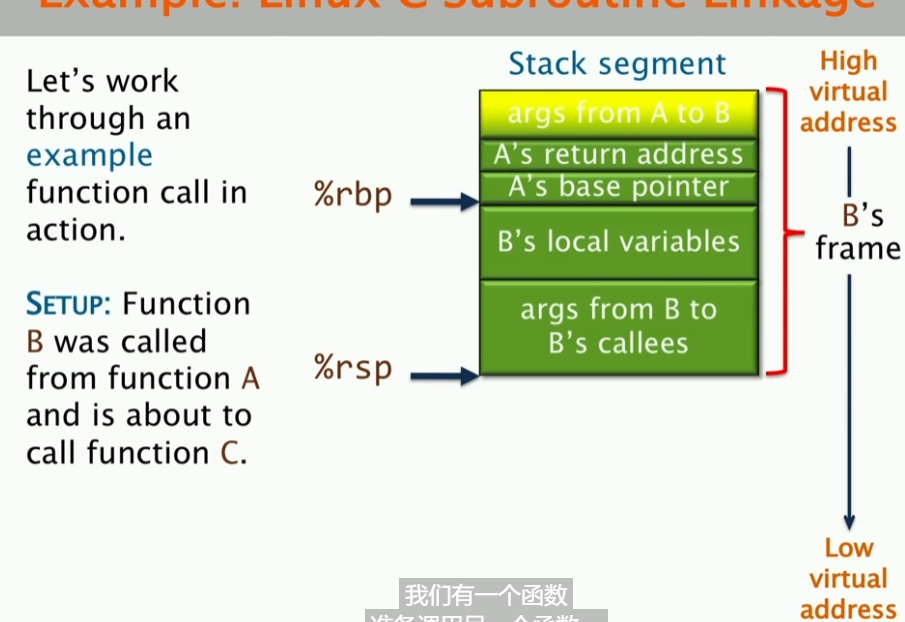
现在有一个场景,即函数B是被A函数调用的,并且这个函数B即将调用函数C。首先,args from A to B是非寄存器参数,我们叫做linkage block,B通过%rbp并且加上一个正的偏移量来访问它(时刻注意栈向下增长,高地址在上面);然后B访问自己的局部变量,是通过%rbp和负的偏移量来访问的;然后B调用C,这个时候,B会把返回地址压入栈中,然后跳转到C的地址,同时C会把自己的局部变量压入栈中;最后C返回,C会把返回值放在%rax中,然后跳转到B的返回地址,B会把返回值放在%rax中,然后跳转到A的返回地址。
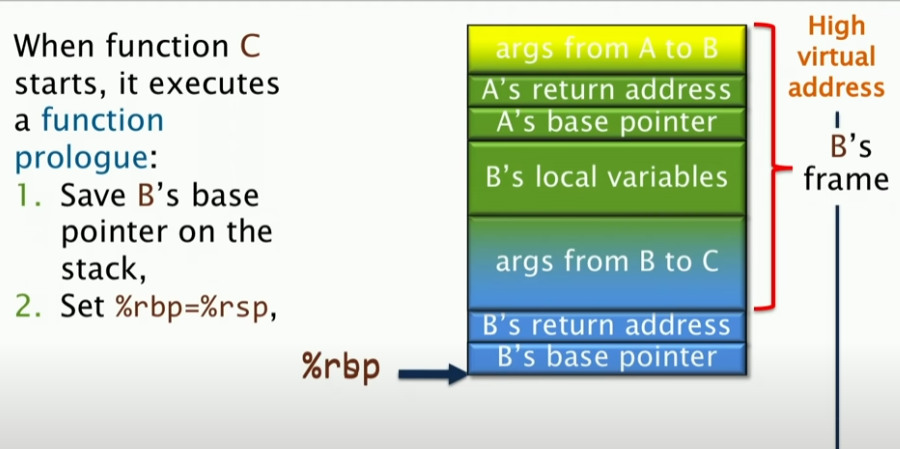
其中,具体的操作如下:当C开始的时候,首先会报错B的基指针地址,就是把基指针地址压栈,随后,设置%rbp = %rsp,这样是为了C继续操作。
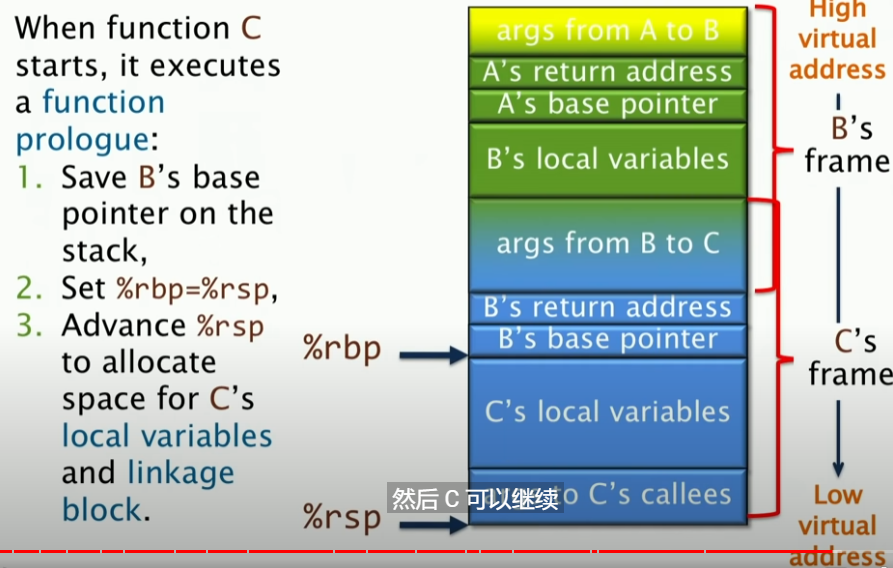
随后,%rsp指针前进,C为自己的局部变量以及linkage block分配空间,然后C就可以开始操作了。
 wechat
wechat alipay
alipay