
性能优化学习笔记4
汇编语言和计算机体系结构
最好的接触底层的接口就是汇编语言
预处理、编译、汇编、链接、加载、执行
为什么我们要查看我们的汇编代码?
- 汇编代码告诉了我们编译器做了什么以及没有做什么
- Bugs会被下降到一个更低的层次
- Reverse engineering,你可以看到别人的代码是怎么工作的(在软件领域,逆向工程一般是指根据机器代码或者字节码转换回高级语言代码)
X86-64 ISA PRIMER
这里有四个主要的概念:
- Registers
- Memory addressing modes
- Instructions
- Data types
x86-64 指令格式 :< opcode > < operand_list >
operand_list 通常由0个、1个、2个或者3个操作数组成(很少有三个的)
正常情况下,所有的operands都是sources,并且有一个同时是source和destination
对于这个语法,主要有两种:AT&T和Intel,其中AT&T是GNU汇编器的默认语法,而Intel是Windows汇编器的默认语法。在指令上面的区别在于AT&T语法中,源操作数在目的操作数之前,而Intel语法中,源操作数在目的操作数之后。
这里先介绍一些常用的Opcodes

- 其中,对于mov指令,就是将一个寄存器的内容放入另一个寄存器中(PS:为什么不叫copy呢? 😠)
- cmov 基于条件的copy(if flag equals to zero and so on…)
- 做符号或者0的扩展,比如将32位变成64位操作数(将32位寄存器值移动到64位上面去,那么高位变换有两种,一种高位补0,一种补符号位)
- push 或 pop 做stack
后面的一些指令不做赘述了
Opcode Suffixes
实际上,Opcode可以被后缀扩充,比如后面可以跟上数据类型的描述或者条件代码
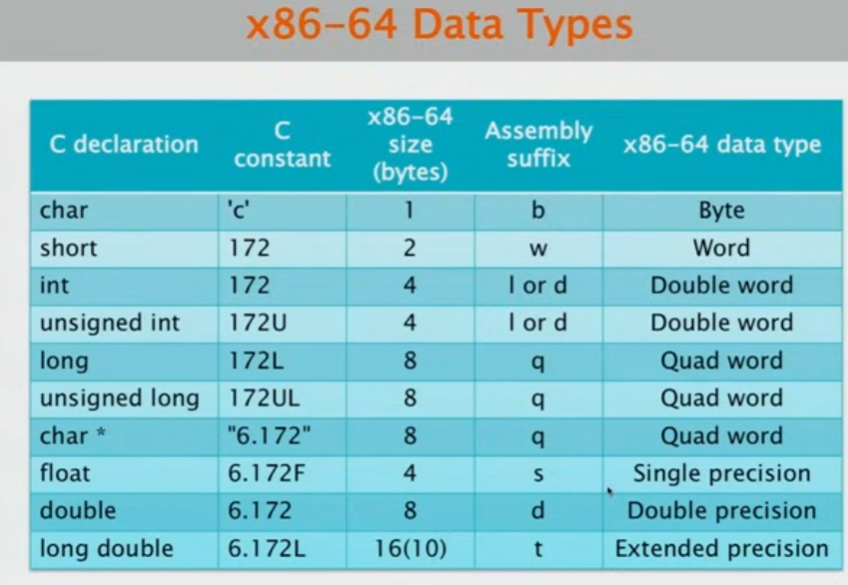
有趣的是,x86-64的架构中,一个四字,是64位,也就是说,一个字在x86-64是16位
Opcode Suffixes for Extension
符号扩展和零扩展,通常要结合两个后缀,因为扩展通常涉及数据类型的变换:
比如: movzbl %al, %edx 意思就是,我们做零扩展,第一个为字节,第二个类型为long类型
[!IMPORTANT]
当一个32位的操作数被加载到64位的寄存器中时,其高位32位通常会被零填充(也就是零扩展)。这是因为在64位系统中,寄存器的宽度是64位,所以当它们需要存储或操作一个32位的数时,需要有一种方法来处理这个位宽的差异。零扩展就是其中一种常见的方法,它通过在高位添加零,将32位的数扩展到64位。
而对于条件操作,通常我们也会使用一个到两个的后缀符号去表明条件代码:
1 | cmpq $4096, %r14 |
很明显,这里比较的是not equal,进行比较期间,会在RFLAGS寄存器中设置一个FLAG,以此来决定是否进行跳转。
所有的条件代码,比较的都是FLAG,只看FLAG,而FLAG与结果相关
三种直接寻址和间接寻址模式
首先是直接寻址:

特别对于直接内存访问(上图的第三条指令):如果CPU直接从内存中获取值,而不是从寄存器或者cache中获取,我们要花费几百个甚至更多时钟周期(处理器太快了!CPU要等待内存将数据传输给CPU 😟)
很明显,如果你把数据放在寄存器里面,你可以在一个周期内访问大多数的寄存器。因此,任何操作我们都是希望数据离CPU更近一点,即使CPU离数据远的情况,即我们需要访存的情况下,我们也希望在访存的时候能干其他事情以提高效率。所以硬件就是通过这一核心思想去组件的!
然后是间接寻址:

第一种就是寄存器内容即地址,第二种即寄存器内容+偏移量就是地址。而对于第三种,这种情况下,通常都是基于Jump指令的,在mov 172(%rip), %rdi这条指令中,172(%rip)表示的是从rip寄存器的当前值开始,向后偏移172字节的地址。这里的偏移是相对于下一条指令的地址,而不是当前指令的地址。这种方法常用于实现位置无关代码(Position Independent Code,PIC),这样的代码可以在内存中的任何位置运行,这在动态链接库和执行时代码生成等场景中非常有用。同时,也有可能并非jump指令,我们也有一种可能,就是把数据存储在这个指令流之中,这样不会破坏任何寄存器。
Base Indexed Scale Displacement
x86-64支持的最常见的间接寻址就是这个方式。这种方式通常用于在堆栈内存中,我们会经常看到这种访问方式。(这种方式更加灵活,可以访问到我想要的数据)

常用的汇编语言使用风格
- 如果我们想清除一个寄存器的内容,我们常常会看到: xor %rax, %rax 【这种操作要比将零常数放到指令里面更快、更容易】
- 想看一个数是否为0,我们使用 test %rcx, %rcx 【test计算的是两个操作数的按位与,并忽视掉最后的结果,仅仅保留RFLAGS】
- 为了进行对齐或者代码大小优化,x86-64通常会有一个nop操作,比如说,如果你想对你的函数在缓存行的开头执行,那么它可以确保你这样执行。所以核心是内存的优化。这个指令如下:data16 data16 data16 nopw %cs:0x0(%rax, %rax, 1) 这条指令什么也不执行,其中data16保留了两个字节的nop
浮点数和矢量硬件
Floating-Point Instruction Sets
现代通常对于浮点数标量的运算都是通过几个不同的指令集实现的。最初的80-86是没有浮点单元的,它们是在软件中实现的,后面随着小型化的发展,它们就被集成了等等。
Vector Hardware
矢量即一组操作数,这组操作数通常需要进行并行处理。因此我们定义矢量长度为包含多少个并行处理操作。
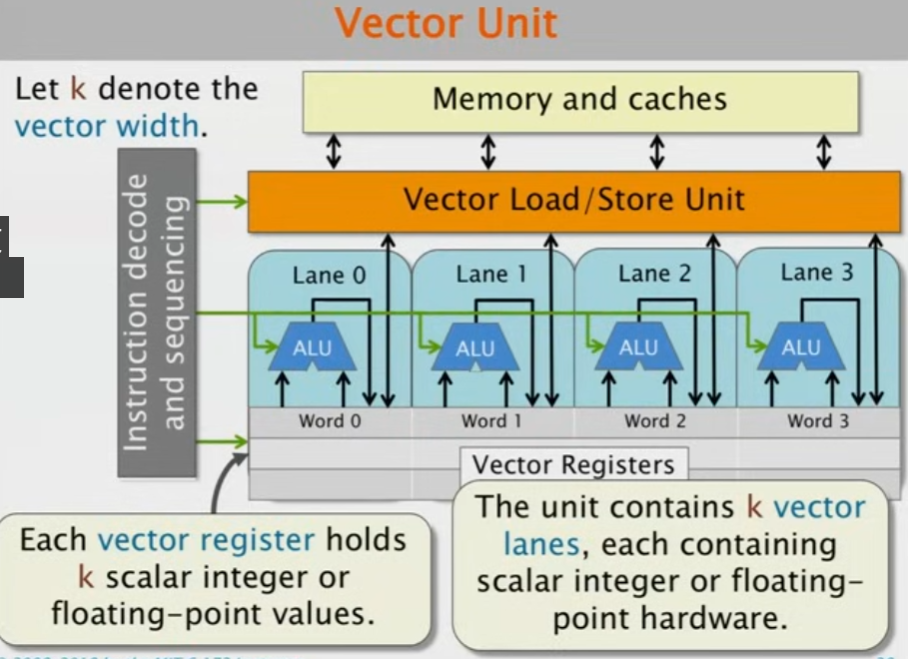
这是一种并行计算的主流方式,比如一个矢量有四个单元,那么就被分为4个lane,四个lane并行去执行任务,但是,它们必须要做完全相同的事情,也就是说,所有的vector lanes的操作都是 lock-step的并且使用的是相同的指令和控制信号,这一点在图中很好看出来。
现代的机器支持对齐和非对齐的矢量处理(即操作数是对齐的),如果不支持未对齐的运算,并且机器不知道你有没有对齐,那么就变成了对标量的处理;如果机器支持未对齐的运算,那么对齐的情况下对比未对齐的情况,对齐的情况要处理更快一点。【现代的机器在对齐和未对齐上都有很好的性能 😳】
而对于某些体系架构,是支持对不同的lane进行shuffle或者提取子集等等操作的,比如我们在pytorch经常看到的scatter操作(分散)
现代的x86-64支持多种不同矢量指令集合,比如 SSE指令集、AVX指令集、AVX2、AVX3等等
体系结构
历史上,人们认为有两种方式可以使得处理器更快:
- 利用并行计算同时执行多个指令
- 利用局部性以最小化数据移动(实际上寄存器的设计就是)
ILP(instruction-level-parallelism)
核心思想是基于不同的pipeline stages,找到去同时执行多条指令的机会,
可是流水线架构的设计,很容易出现stall,这种stall是由于hazards导致的,有三种hazards:
- 结构冒险:两条指令都要用同一个功能单元
- 数据冒险:一条指令以来上一条指令的管道输出
- 控制冒险:比如跳转指令,这会使得取指和译码被延迟
对于数据冒险,有三种类型:

其中,对于第三种,实际上我们可能会以为这两条指令的实际效果等同于执行最后一条指令,但是实际上并不是。
原因如下:
- 可能第一条指令只是想去设置一些FLAGS
- 可能这个指令使用了某个寄存器的别名,也就是说这个寄存器只是别名而已
Complex Operations
有一个特别值得关注的复杂运算是FMA,即fuse-multiply-adds,这个是浮点数的乘加运算,这个之所以重要,是因为线性运算的存在。即点积
而体系结构是如何设计的呢?——其思想就是为这些复杂的操作设计专门的运算单元、寄存器,因此流水线的pipeline就不止五个了

这样,处理不同数据,走的路径也就不同。那么,设计师对于并行的思想就是在一个周期中去提出多个指令,而不是像传统的流水线CPU那样一个周期只进行一个操作。因为它们互不干扰
Bypassing
与其等待上一条数据被存到寄存器里面,不如设置一个旁路,识别这种特殊情况,然后直接馈入数据给下一条需要的指令
不需要特别了解,后面体系架构再学了 😰

 wechat
wechat alipay
alipay